こちらの記事の後編です、背景など詳細はそちらをご覧ください。

MatillionとForecastFlowを連携する(予測編)
全体像
訓練編とは若干構成が異なります。なぜかというと、訓練では「じゃ、これでモデル作成、よろしく」って感じで丸投げしたらよかったんですが、推論は結果を返してもらう必要があるからです。
また訓練編同様に、大前提として予測用一枚表テーブル作成までは完了しているものとします。
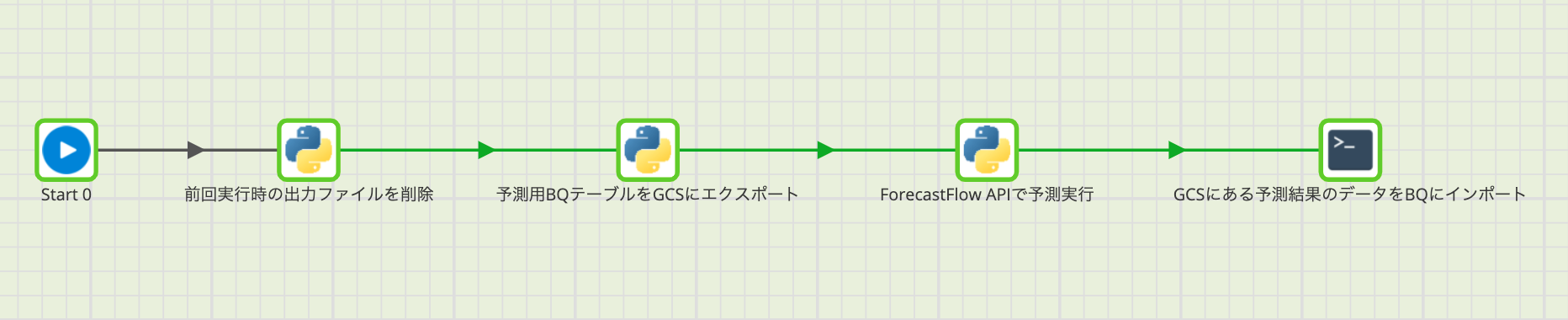
全体像としては以下のような感じです。(1以降を説明します)
(0)データ収集・一枚表作成
(1)前回実行時の出力ファイルを削除(定期的に予測を実行する場合のみ)
(2)BigQuery(BQ)の予測用一枚表テーブルをCloud Storage(GCS)にエクスポート
(3)ForecastFlow APIによる予測実行
(4)GCSに返ってきた予測結果をBQにインポート
なお以下で説明するフローではJob Variablesならびに、Environment Variablesで以下の変数を定義しています。実際に動かす際は、ここだけご自身のものに書き換えていただければ、コンポーネントの中身自体はコピペで行けます。
| 変数名 | 説明 |
|---|---|
| GCP_PROJECT | GCPのプロジェクト名 |
| BQ_DATASET_ID | (BQ)訓練用テーブルを格納しているデータセット名 |
| BQ_LOCATION | (BQ)訓練用テーブルのロケーション |
| GCS_BUCKET_NAME | (GCS)移行先のバケット名 |
| GCS_PREFIX | (GCS)移行先のディレクトリ階層 |
| PREDICT_FEATURE_NAME | (BQ, GCS)予測用一枚表のテーブル/ファイル名称 |
| PREDICT_SCORE_NAME | (BQ, GCS)予測スコアのテーブル/ファイル名称 |
| FF_EMAIL | (ForecastFlow)アカウント情報:メールアドレス |
| FF_PASSWORD | (ForecastFlow)アカウント情報:パスワード |
| FF_PROJECT_ID | (ForecastFlow)プロジェクトID |
| FF_TEAM_ID | (ForecastFlow)チームID |
| FF_TRAINED_MODEL_ID | (ForecastFlow)訓練済みモデルID |
ちなみに、ForecastFlowのチームID・プロジェクトID・訓練済みモデルIDはWeb上のURLを見ればすぐにわかります。xxxがチームID、yyyがプロジェクトID、zzzが訓練済みモデルIDです。

(1)前回実行時の出力ファイルを削除(定期的に予測を実行する場合のみ)
ここは定期的に実行される方以外、読み飛ばしてください。運用時の話です。
GCSにある前回実行時の予測用一枚表・予測スコア結果のファイルを削除します。
(少々細かいんですが)なぜかというと、この後説明するように、ファイル出力を複数ファイルに分けて実行することを想定しているからです。ファイルが一つだけであれば、上書きすれば構わないんですが、複数出力する場合はいくつのファイルに分割するかをGCPに任せるため、GCPさんの気分次第でファイル数が変わりうるためです。
例えば、スコアテーブルを考えたとき、前回は100ファイルに分けて出力していたところを、今回は80ファイルに分けて出力したとすると、20ファイルは上書きされず、前回の結果が残ったままになります。従って、これをそのまま一括で取り込んでしまうと、80ファイル分の今回の結果+20ファイル分の前回の結果となってしまい、辻褄が合わなくなってしまいます。
少々前置きが長くなりましたが、コードサンプルはこちらです。
- predictionとあるのが予測用一枚表ファイルを
- scoresとあるのが予測スコアファイルを
それぞれ表します。
from google.cloud import storage
client = storage.Client()
def delete_blobs_by_prefix(bucket_name, prefix):
bucket = client.get_bucket(bucket_name)
list_blobs = []
for blob in bucket.list_blobs(prefix=prefix):
blob.delete()
delete_blobs_by_prefix(GCS_BUCKET_NAME, f'{GCS_PREFIX}/{FF_TRAINED_MODEL_ID}/{PREDICT_FEATURE_NAME}_prediction')
delete_blobs_by_prefix(GCS_BUCKET_NAME, f'{GCS_PREFIX}/{FF_TRAINED_MODEL_ID}/{PREDICT_FEATURE_NAME}_scores')
(2)BigQueryの一枚表テーブルをCloud Storageにエクスポート
訓練用とほぼ同じです。
- 移行元BQ上のテーブル指定
- →移行先GCS上のファイルパス指定
ただし、以下の2点は変わっているので注意してください。
- ファイル形式をcsvではなくparquet(ファイルの圧縮率が格段に向上し、ファイル連携スピードが速くなる)
- ワイルドカードで複数ファイルを出力(BQからGCSへのファイルエクスポートは1GBを超える場合、このように分割する必要がある)
もちろん、そこまで予測用ファイルが大きくない場合は、訓練時同様csv形式で一つのファイルに吐き出してもらっても構いません。
ですが、一般的に予測用データは訓練用データに比べ大きくなりがちなこともあり、特に強いこだわりがない場合はparquetでの出力をオススメいたします。
from google.cloud import bigquery
bq_client = bigquery.Client()
# BigQueryのテーブル情報を取得するためのクラス
class BqTable:
def __init__(self, project, dataset, table_name):
self.project = project
self.dataset = dataset
self.table_name = table_name
def table_ref(self):
dataset_ref = bigquery.DatasetReference(self.project, self.dataset)
table_ref = dataset_ref.table(self.table_name)
return table_ref
# GCSにファイル出力するためのクラス
class GCS:
def __init__(self, bq_client, bucket_name, prefix):
self.bq_client = bq_client
self.bucket_name = bucket_name
self.prefix = prefix
def _destination_uri(self, file_name):
return f'gs://{self.bucket_name}/{self.prefix}/{file_name}'
def export_table_as_parquet(self, bq_table, file_name, location):
destination_uri = self._destination_uri(file_name)
bq_ext_job_config = bigquery.ExtractJobConfig(
compression=bigquery.Compression.SNAPPY,
destination_format=bigquery.DestinationFormat.PARQUET
)
table_str = f'{bq_table.project}.{bq_table.dataset}.{bq_table.table_name}'
extract_job = self.bq_client.extract_table(
table_str, destination_uri, location=location, job_config=bq_ext_job_config
)
extract_job.result()
# 対象テーブルをparquet形式でGCSに出力
table_to_export = BqTable(GCP_PROJECT, BQ_DATASET_ID, PREDICT_FEATURE_NAME)
GCS(bq_client, GCS_BUCKET_NAME, GCS_PREFIX).export_table_as_parquet(
table_to_export, FF_TRAINED_MODEL_ID + '/' + PREDICT_FEATURE_NAME + '_prediction*.parquet', BQ_LOCATION
)
(3)ForecastFlow APIによるモデル作成
訓練編同様コードサンプルを貼り付けるに留めます。流れとしては以下の通り。
- ForecastFlowのユーザー情報を認証
- →連携するGCS上のファイル情報取得
- →GCS上のファイルをForecastFlowに連携
- →予測実行
- →予測終了まで待機
- →予測スコアをGCSに保存
from google.cloud import storage
from forecastflow import DataSourceLabel, FileType, Model, Prediction, User, ClassifierTrainingSettings, Project
from forecastflow.satellite.google.cloud import storage as ff_storage
from forecastflow.enums import ClassificationMetrics
# ForecastFlowのユーザー認証・予測に使うモデル情報の設定
ff_user = User(FF_EMAIL, FF_PASSWORD)
ff_project = Project(ff_user, FF_PROJECT_ID, FF_TEAM_ID)
ff_model = Model(project=ff_project, model_id=FF_TRAINED_MODEL_ID)
# ForecastFlowに連携する予測用データセット
gcs_client = storage.Client()
gcs_prediction_file_prefix = f'{GCS_PREFIX}/{FF_TRAINED_MODEL_ID}/{PREDICT_FEATURE_NAME}_prediction'
bucket = gcs_client.get_bucket(GCS_BUCKET_NAME)
list_blobs = []
for blob in bucket.list_blobs(prefix=gcs_prediction_file_prefix):
list_blobs.append(f'gs://{GCS_BUCKET_NAME}/{blob.name}')
uris_import = list_blobs[0:]
# データソースの作成
data_source_pred = ff_storage.import_data_source(
uri=uris_import,
project=ff_project,
name=f'Prediction Dataset: {FF_TRAINED_MODEL_ID}', # データソースの名前
label=DataSourceLabel.PREDICTION, # データソースのラベル
filetype=FileType.PARQUET, # データソースのファイル形式 [CSV, TSV, PARQUET]
description=None, # 説明文(省略可能)
skip_profile=True, # プロファイルをスキップする場合はTrue(現在のデータ容量では使用上Falseにすると処理時間が極端に長くなる)
client=gcs_client # GCSクライアント
)
# 予測実行
prediction = ff_model.create_prediction(
data_source=data_source_pred,
name='prediction',
filetype=FileType.PARQUET # 予測結果のファイル形式
)
# 予測終了まで待機
prediction.wait_until_done()
# 予測結果をGCSに保存
gcs_result_file_prefix = f'gs://{GCS_BUCKET_NAME}/{GCS_PREFIX}/{FF_TRAINED_MODEL_ID}/{PREDICT_FEATURE_NAME+"_scores"}'
ff_storage.export_prediction(
prediction=prediction, # ForecastFlowパッケージの予測用インスタンス
uri_prefix=gcs_result_file_prefix, # 出力先URIのprefix(ファイル容量が大きい場合、複数ファイルに分割して吐き出される)
client=gcs_client # GCSクライアント
)ここでもう一点注意があります。
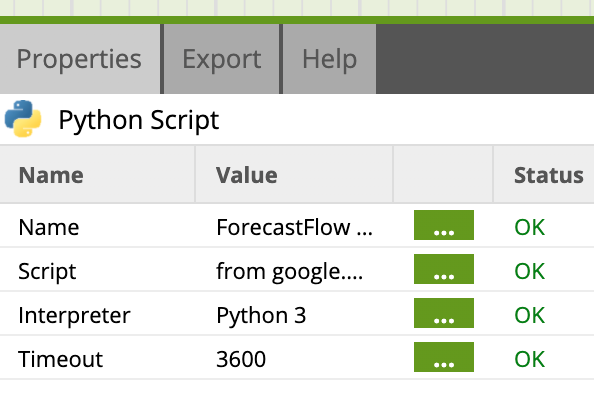
推論が長期間に及ぶことが想定される場合は、PythonコンポーネントのTimeout時間を長めに設定しておきましょう。そうでないと途中でタイムアウトしてしまいます。
(下の例では1時間(3600秒)に設定)
(4)GCSに返ってきた予測結果をBQにインポート
GCSに結果があればいいという方は読み飛ばしてください。
コードサンプルは以下の通りで、これはBash Scriptコンポーネントで行います。
bq --location=$BQ_LOCATION load \
--replace \
--source_format=PARQUET \
$BQ_DATASET_ID.$PREDICT_SCORE_NAME gs://$GCS_BUCKET_NAME/$GCS_PREFIX/$FF_TRAINED_MODEL_ID/$PREDICT_FEATURE_NAME"_scores*.parquet"
以上です。
今後もこの記事を更新するか、もしくは別の場所でコードスニペットを管理するか、いずれにしても何らかの方法でアップデートをお伝えいたします。