
弊社では、地理空間データの分析および可視化のためのサービスとしてLLocoを提供しています。

私はこのサービスの中で、「郵便番号」と「町丁目境界データ」を住所でマッチングさせたデータセットの開発を主に担当しています。
本記事ではその中で特に大変だった、住所の「名寄せ」について前中後編に分けて紹介します。前編は主にLLocoの中身について紹介する導入部です。
LLocoの中身
LLocoの作成においては、日本郵便が提供する郵便番号データおよびe-Statが提供する統計地理情報システムの境界データを利用し、下の画像のようなイメージでそれらのデータを結びつけています(ちなみにこれらは商用利用も可能なオープンデータとなっています)。
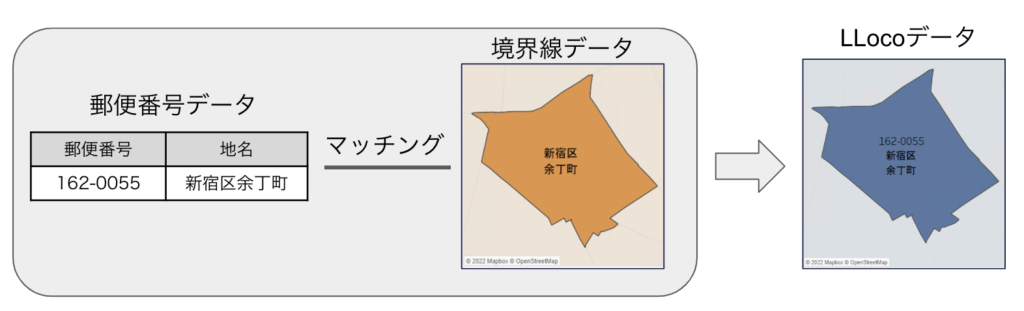 LLocoでの郵便番号と境界データのマッチングのイメージ
LLocoでの郵便番号と境界データのマッチングのイメージこの作業を日本全国に対して行うことで、LLocoでは郵便番号から対応する地域の位置や統計データの把握、地名やGPSの位置情報から対応する郵便番号の取得が可能となり、商圏分析やエリアマーケティングに役立てることができます。
ちなみに日本全国で郵便番号はおよそ11万件、境界データはおよそ22万件あります。たくさんありますね!
LLocoでの「名寄せ」とは
ここで言う住所の「名寄せ」とは、「異なるデータベースで同じ地域を表しているデータをマッチングさせ、対応関係を明らかにする」作業を指します。
画像で見せたようなマッチングであれば、SQLなどを用いて一瞬でできるのでは? と思う人もいるかもしれませんが、実際の中身はもっと複雑で、例えば次のような事象があります。
- 郵便番号に対応する境界データが複数ある
- 逆に1つの境界データの中に複数の郵便番号の区域が含まれている
- 郵便番号と境界データで住所に細かい違いがある
- etc…
e-Statが提供している境界データは「町丁目粒度」と呼ばれるもので、本来郵便番号よりも1つ細かい単位であるため、ほとんどの場合は❶のパターンとなっており先ほどの画像のように1:1対応しているものはむしろレアケースです。
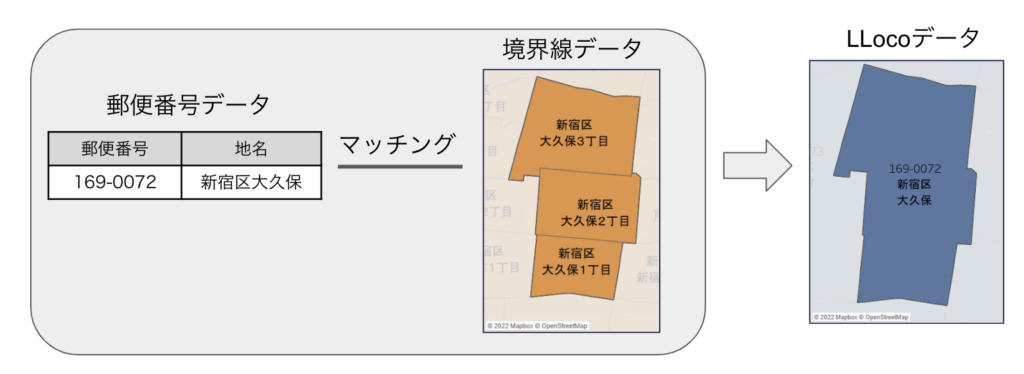 ❶ 郵便番号に対応する境界データが複数ある例
❶ 郵便番号に対応する境界データが複数ある例上記のように、境界データでは「丁目」で分かれているけど郵便番号はそうではない例は分かりやすいと思います。この場合、郵便番号に対応する境界データを漏れなく抽出し、統合する必要があります。
とは言いつつも、行政上の都合かなぜなのか、逆の❷のパターンもごく稀に存在します。
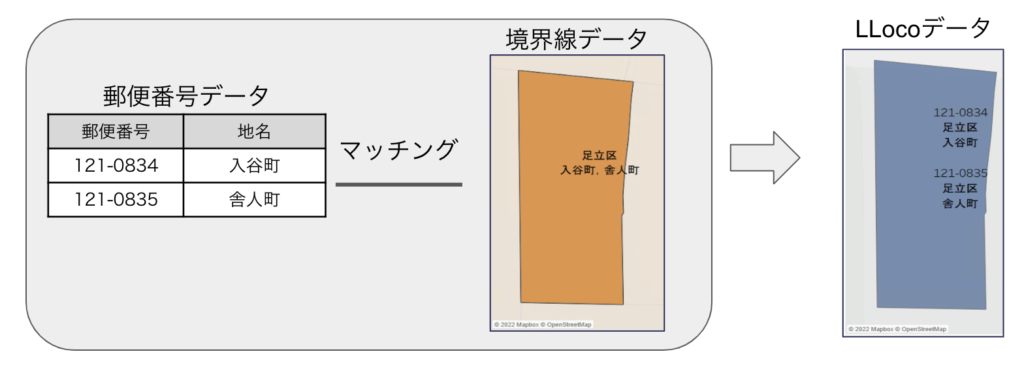 ❷ 1つの境界データの中に複数の郵便番号の区域が含まれている例
❷ 1つの境界データの中に複数の郵便番号の区域が含まれている例ここでは境界データを郵便番号の単位で正しく分けることはできないため、LLocoでは「複数の郵便番号が含まれる地域」として扱い、その内訳は別途マスタデータを用意して参照できるようにしています。
そしてこれらとは別問題として結構な割合で存在するのが❸であり、今回の話で扱いたいメインとなります。
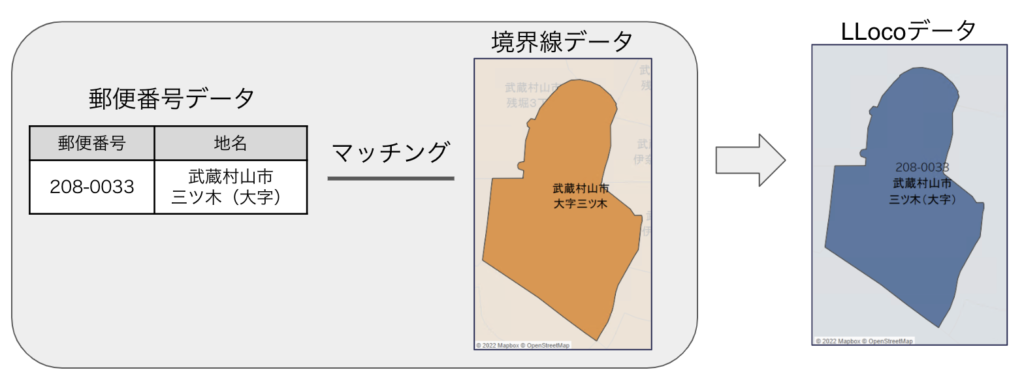 ❸ 郵便番号と境界データで住所に細かい違いがある例
❸ 郵便番号と境界データで住所に細かい違いがある例上記の例では、郵便番号データ上で「三ツ木(大字)」、境界データ上で「大字三ツ木」となっており、人の目では同じ場所を表しているだろうと判別できるものの、そのままでは自動で結びつけることはできません。
そのため、これらが同一の地名だとわかるように「名寄せ」を行う必要が出てくるわけです。
この❸について、日本全国で具体的にどのようなパターンがあるのか、どう対処したのかなどを次回以降紹介していきます。

















