
ことの発端は友人から投げかけられた一つの疑問でした。

社会教育調査ハンドブック 国立教育政策研究所社会教育実践研究センターの7.4章
(「社会教育調査ハンドブック ① 全体版 PDF」の項目)

これってどういうことかわかる?「容易に想像できよう」ってあるけどあんまり想像できない。証明もできる?
直感的になんとなく気持ちはわかるけど、証明となるとパラメータが多くて場合わけするのも大変そう……というのが第一印象だったので、実験的にやってみて納得を得られる方向性でいくことにしました。その時の備忘録のようなものです。
実験のセットアップ概要
大まかな流れとしては、日本人の年収分布を仮想的に作成し、そこから1段の多段抽出法と無作為抽出法のそれぞれで標本誤差=標本標準偏差の分布の広がりを確認・比較します。(年収なのは別に理由はありません、都道府県ごとに違いが出そうなものであればなんでもいいです。)
具体的には以下のようなステップで確認していきます。
【step1】日本人の年収分布を仮想的に作成
(1)都道府県ごとに平均年収を決定:平均600万円、標準偏差200万円の正規分布から無作為抽出
この操作で適当に決めた都道府県ごとの平均年収は以下の表のようになります。
当然適当なセットアップで生み出された世界の話なので現実とは乖離してますが、例えば「愛知県(仮想)」は平均年収が最下位で208万円、「島根県(仮想)」は平均年収がトップで970万円となっていることがわかります。
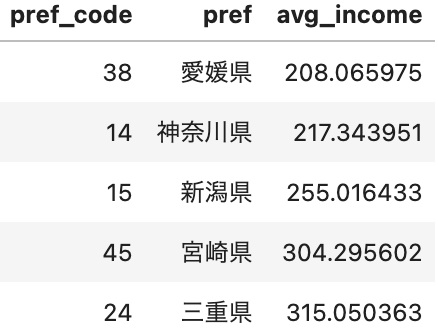 仮想的な平均年収が低い都道府県トップ5
仮想的な平均年収が低い都道府県トップ5
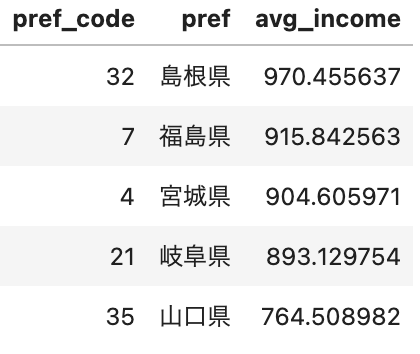 仮想的な平均年収が高い都道府県トップ5
仮想的な平均年収が高い都道府県トップ5
(2)各都道府県の人口が10万人として、年収の分布を作成:各都道府県の平均年収、標準偏差30万円の正規分布から無作為抽出
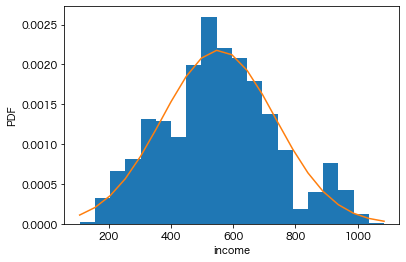 仮想的に作成した「日本(仮想)」の年収分布(人口470万人)
仮想的に作成した「日本(仮想)」の年収分布(人口470万人)はい、これで人口470万人(=47*10万人)の仮想的な「日本(仮想)」の年収分布データを得られたことになります。平均と標準偏差は以下の通り。
いちいち仮想的とか書くのもまどろっこしいので、これ以降はこの集団が日本人全体の母集団だと思ってください。ここからはこの母集団からサンプリングを行って、平均年収を推定し、その時の標本誤差=標本標準偏差を確認していきます。
【step2】サンプリング手法ごとにシミュレーション実施
step1で生成した母集団から(1)無作為抽出(2)多段抽出、それぞれでサンプリングを行い、どちらの標本誤差が小さいか比較していきいます。
無作為抽出でサンプリングした場合
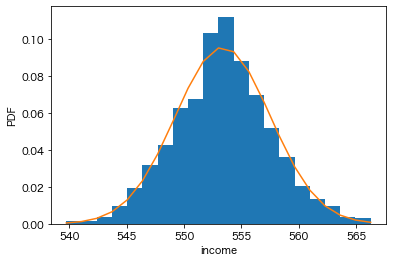 無作為抽出で調査を1,000回繰り返し行った時、各調査で得られた平均の分布
無作為抽出で調査を1,000回繰り返し行った時、各調査で得られた平均の分布一つのサンプリングが1回の調査に対応するので、この分布は「1,000個のパラレルワールドで行った時のそれぞれの調査から得られた平均の分布」とした方がわかりやすいかもしれません。
平均(=平均の推定値)はほとんど母集団の平均と合致しており(不偏性)、標準偏差が4.2万円であることから、いい精度で平均を推定できていることがわかります。
一段(都道府県)の多段抽出法でサンプリングした場合
以下のセットアップでサンプリングを行います。
N_PREF、つまり調査対象に選ばれる都道府県の数がパラメータなので、それを変えて結果を確認してみます。
N_PREF=5の場合
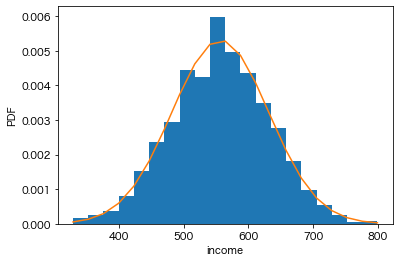 多段抽出(N_PREF=5)で調査を1,000回繰り返し行った時、各調査で得られた平均の分布
多段抽出(N_PREF=5)で調査を1,000回繰り返し行った時、各調査で得られた平均の分布平均(=平均の推定値)が母集団の平均とほとんど合致していることは無作為抽出の場合と同じですが、標準偏差が75.2万円と非常にばらつきが大きいです。これは特定の都道府県のみからサンプリングを行うため分布が偏ってしまうことに起因します。
N_PREF=10の場合
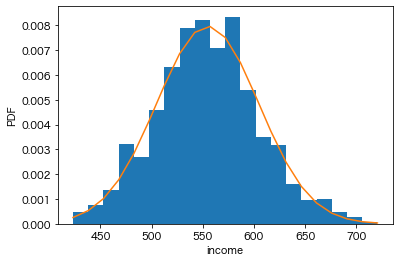 多段抽出(N_PREF=10)で調査を1,000回繰り返し行った時、各調査で得られた平均の分布
多段抽出(N_PREF=10)で調査を1,000回繰り返し行った時、各調査で得られた平均の分布N_PREF=5の時とほとんど同じ結果ですが、標準偏差は50.1万円と小さくなっています。これは対象都道府県を増やしたことで分布の偏りが多少是正されたことが理由です。
【step3】サンプリング手法同士で標本誤差を比較
このノリでN_PREF=5,10,20,47の時の結果と無作為抽出(ランダムサンプリング)の結果を比較してみましょう。上で確認したサンプリング結果にN_PREF=20,47の場合を加えて同時にプロットしたのが下のグラフです。
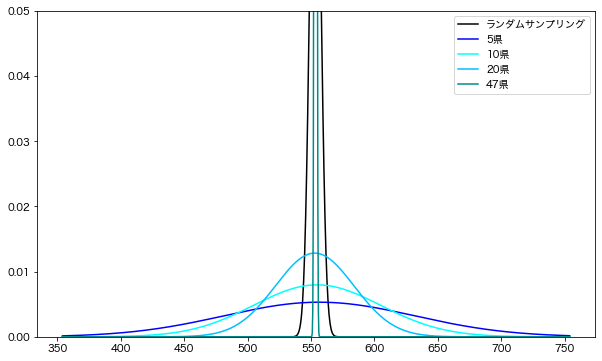 1,000回繰り返し調査をしたときの平均の分布。無作為抽出の場合と多段抽出(N_PREF=5,10,20,47)の場合を同時にプロット。N_PREF=47の時のみサンプルサイズが1,974(=42*47)であることに注意。他は2,000で統一
1,000回繰り返し調査をしたときの平均の分布。無作為抽出の場合と多段抽出(N_PREF=5,10,20,47)の場合を同時にプロット。N_PREF=47の時のみサンプルサイズが1,974(=42*47)であることに注意。他は2,000で統一
これをみると無作為抽出した場合に比べてN_PREF=5,10,20の多段抽出で明らかに分布が広がっている、つまり標本誤差が大きいことがわかります。一方で、N_PREF=47の場合のみ、無作為抽出よりも標本誤差が小さいです。これは都道府県ごとに完全に同一数抽出したことで、都道府県ごとの抽出数が偏らないことに起因していると考えられます(無作為抽出の場合、都道府県ごとに抽出数に多少の偏りが出る)。
結論
それでは結論を書きつつタイトルの疑問に答えましょう。
平均の推定量の期待値はどちらの手法も母集団の平均の値と近い(不偏推定量)
→どちらの手法においてもバイアス(=母集団平均と平均の推定量の期待値の差、系統誤差)はない
平均の推定値の標準誤差は無作為抽出に比べ
- 選出される県が少ない場合多段抽出の方が大きい
- ほとんど全ての都道府県から抽出できる場合、多段抽出の方が小さい
ただ、多段抽出法は日本人全体から抽出して調査をすることが予算などの都合上難しい場合(*1)に行われることが多いようですので、全ての都道府県から同数だけ抽出する、というケースはあまり想定されてない気がします。
だから、冒頭に紹介したハンドブックでは「標本誤差が大きくなることは、容易に想像できよう。」と書いてあったのでしょう。うーん、そこまで『容易に』想像はできない気がしますが、実験を通して言わんとしていることは理解できました。
それと以下の点は誤魔化してるので、気になる人は考えてみてください(丸投げ)














