
こんにちは!今回はAzure SDK PythonでAzure Blob Storageへデータを送受信する方法と、注意点をまとめていきます。
事前準備
ローカルサーバーなどでAzure Cloudの操作を行うために認証キーを取りに行きます。
まずは、Azure Portalから操作を行いたいストレージアカウントに移動します。その後、左側のタグの「セキュリティ > アクセスキー」を選択します。
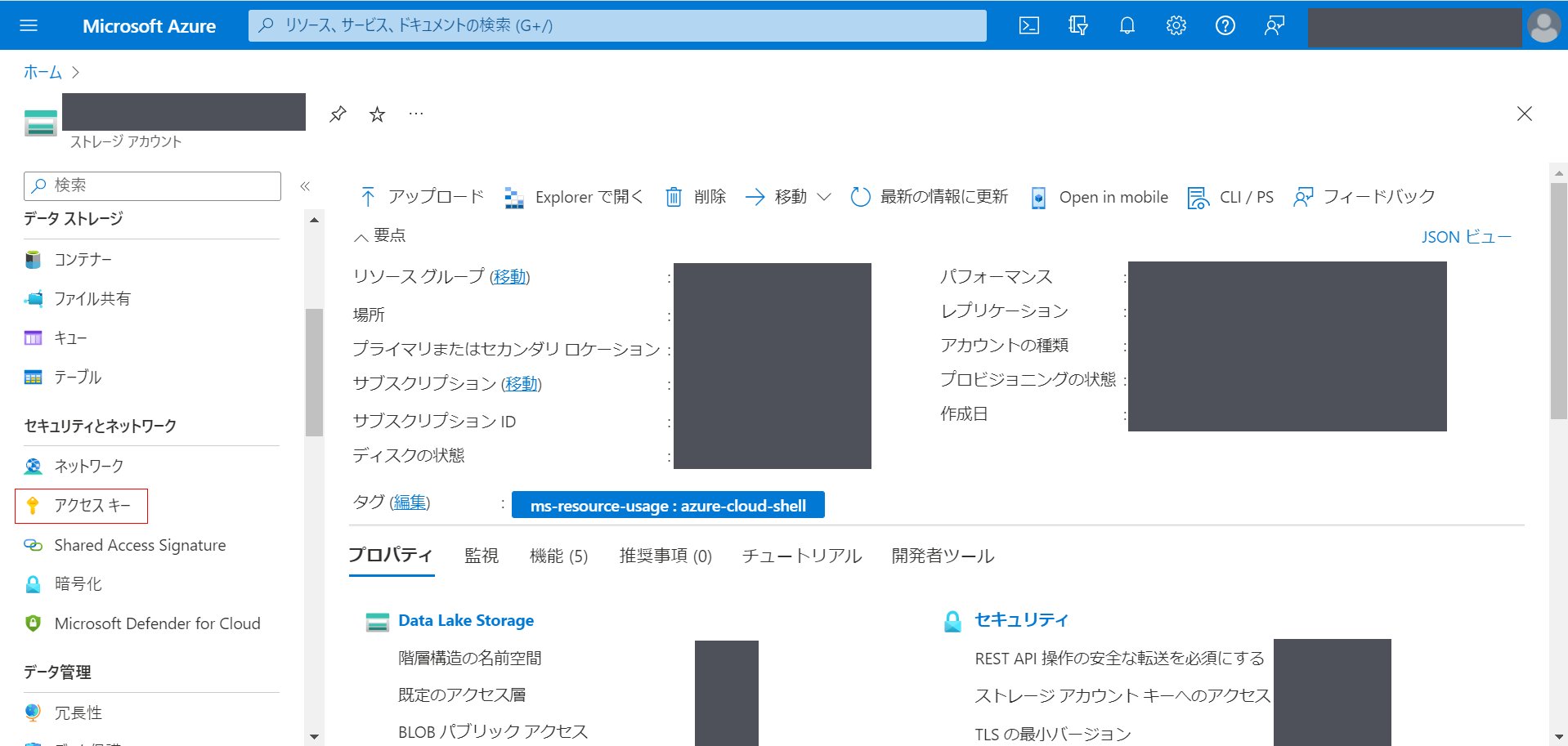
 その後、key1またはkey2の「接続文字列」を表示し、そこの文字列を記録しておきます。
その後、key1またはkey2の「接続文字列」を表示し、そこの文字列を記録しておきます。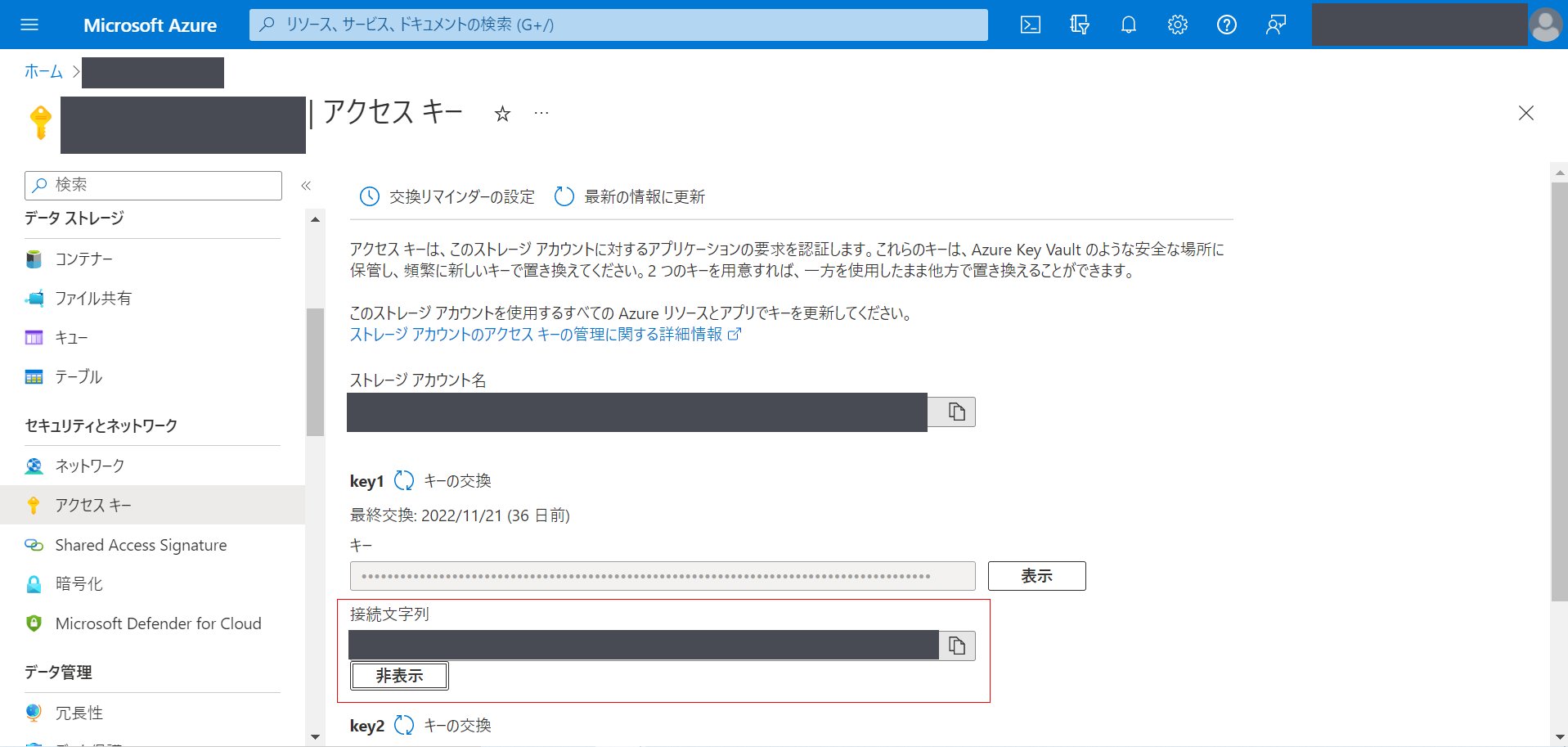
これで最低限の準備は終了です。実際にBlobの読み書きを行う場合はさらにコンテナーを作成しておきましょう。
Azure SDK Pythonのインストール方法
Azure SDK Pythonでは主に次のようなことができます。
- コンテナーの作成、削除
- コンテナー内のBlobのダウンロード
- ローカルサーバーのデータをBlobとしてアップロード
コンテナー、Blobって何?という人はドキュメントを参照ください。
Python packageのインストール(ドキュメント)
pipの場合
pip install azure-storage-blobconda の場合(チャネルの追加が必要)
conda config --add channels "Microsoft"
conda install azure-storage-blob表形式データを読み書きする場合にはPandasで簡単に読み込むことができます。(Pandasのバージョン1.2以降で対応)
pip install 'pandas>=1.2'表形式データの読み書き
読み書きのための大まかな手順(Blob内のデータは同じ構造で縦結合できるケースを想定)
- Azure Storageアカウントの認証を通す
- コンテナーを指定し、Prefix検索でBlobのリストを取得する
- リストをfor文で逐次読み取り
- Pandasで書き込み
スクリプト例は次のようになります。
from azure.storage.blob import BlobServiceClient
import pandas as pd
# Azure Storageアカウントの接続文字列
connection_str = '接続文字列'
# コンテナーの名称
container_name = 'コンテナー名'
# Azure Storageアカウントの認証、コンテナーの指定
blob_service_client = BlobServiceClient.from_connection_string(
conn_str=connection_str
)
container_client = blob_service_client.get_container_client(
container_name
)
# 読み取り候補のリストの取得
blobs = container_client.list_blobs(
'Blob候補'
)
# リストごとに表形式データの読み取り
# Joblibなどで並列化も可能
dfs = []
for b in blobs:
dfs.append(pd.read_csv(
f'abfs://{container_name}/{b.name}',
storage_options={
'connection_string': connection_str
}
))
# 全Blobの縦結合
df = pd.concat(dfs)
# Azure Blob Storageへの書き出し
# JSON形式やParquet形式での書き出しも可能
df.to_csv(
f'abfs://{container_name}/{'Blobの名称'}',
index=False,
storage_options={
'connection_string': connection_str
}
)注意点
Blobリストの取り込みの仕様面で癖があり、注意が必要です。
リストの絞り込みがPrefix検索しか対応していない
正規表現などと組み合わせる場合にはif文を使う必要があります。
一度に取り込めるリスト数の上限が5,000個
候補のBlobを一気に取り込めないので5,000個以上のBlobを取り込む場合はfor文の実行中に読み込みの時間がかかります。
なので、効率よくAzure Blob Storageの読み書きを行う場合は以下のことに気を付けると実行時間、費用が削減できます。
Blobの階層性をPrefix検索で取り出せるようにする
例えば、日付でデータを取り出したい場合は日付ごとにBlobの階層を分けると素早く取り出せます。
読み取るファイル数を減らす
ファイル数を減らすことで、読み取りの遅延とAzure Cloudへのリクエスト回数を削減できます。
ということで、今回はAzure SDK PythonでAzure Blob Storageへデータを送受信する方法をご紹介しました。
個人的にはPandasの関数でクラウドに接続できるのがかなり便利だと思います。それと、Prefixによる検索やパスの取り込み量の制限など気を付けることが沢山あり通常のデータ分析とは違う視点を持つことが大事そうです。
最後までお読みいただきありがとうございました。















