
セマンティックセグメンテーションにおいて従来のエンコーダ・デコーダ型モデルよりさら高精度を達成した手法の1つはDeepLabです。その最大の特徴は、通常の畳み込みの代わりに、Atrous Convolution(拡張畳み込み)を採用している点です。
Atrous Convolutionは、Dilated Convolutionとも呼ばれ、エンコーダで畳み込み演算に使うフィルターの要素の間に一定間隔で空白(Dilation)を挿入します(図1)。このような隙間の空いた歯抜けのフィルタを用いて畳み込み演算を行うことで画像に対して従来よりも「疎」な畳み込み演算を行うことになります。そうすると、一回の畳みでカバーできる画像の面積が増えます。プーリングを行わず、特徴マップの解像度を大きく低下させることなく、パラメータ数を増やさずに比較的広範囲の情報を利用した画素分類が可能になります。
SegNetやU-Netのようなエンコーダ・デコーダ型モデルは、画像を段階的に圧縮して特徴を抽出し、その後アップサンプリングによって空間解像度を回復することで、画素ごとの分類(セグメンテーション)を実現する手法です。これらのモデルのエンコーダで行われるプーリングや畳み込みによって特徴マップの解像度が一度低下してしまいます。そうすると、細かい構造の復元がアップサンプリング処理に依存することになります。上記の課題に対して、特徴マップの空間解像度を可能の限り保ちながら広い受容野を確保するという発想から提案されたのがDeepLabです。
(補足)U-Netではスキップ接続によって境界情報はかなり改善されているものの、依然としてエンコーダで一度特徴マップの解像度が下がる問題が残ります。そこで解像度を下げないのがDeepLabの設計思想です。
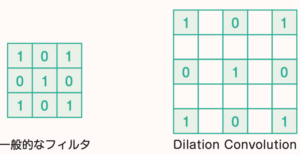
図1:(左)一般的な畳み込み層で用いられるフィルタの例 (右)Atrous Convolution に用いられる一定感アクで歯抜けを持つフィルタ
出典:『G検定 最強の合格問題集』
■DeepLabの発展版モデル
DeepLabの発展版DeepLab v2では、異なる拡張率(dilation rate)を持つAtrous Convolutionを並列に配置するASPP(Atrous Spatial Pyramid Pooling)を取り入れています。これにより、複数のスケールの特徴を同時に抽出・利用可能になり、物体の大きさが異なる場合でも柔軟に対応できるようになりました。
DeepLab v3+ではASSPとエンコーダ・デコーダ構造を組み合わせており、さらに精緻な境界解析を実現できました(図2)。さらに、Depthwise Separable Convolutionを採用することで処理速度と計算量の面でも改善を果たしました。
また、DeepLab のエンコーダでは特徴抽出層にResNet101を使用していたのに対し、DeepLab V3+ ではそれをセグメンテーション用に改良した Xception に変更したこともセグメンテーションの品質の向上に寄与しています。

図2:DeepLab v3+ではASSPとエンコーダ・デコーダ構造を組み合わせています。
出典:https://arxiv.org/abs/1802.02611
近年の物体認識では、高精度なセマンティック・セグメンテーションとともに、計算の速度やリアルタイム性が重視されています。DeepLab v3+ と並んで、別の記事で紹介するPSPNet がセマンティック・セグメンテーション用の標準的モデルとして普及しています。













