
前回は、『ウェブからデータを収集する手法を俯瞰(その1)』において、SDKやAPIを使ってデータ取集する話をしました。

APIが提供されていない、一般的なウェブサイト上のデータを収集し、分析に使用したい場合はクローリングとスクレイピングを活用すると便利です。
ウェブサイトのデータの構造
ウェブサイトのコンテンツは、HTML (Hyper Text Markup Language)という種類のテキストデータで構成されています。HTMLはウェブサーバー上で生成または保管されています。
任意のウェブページに行き、そのページのHTMLを確認できます。例えばWindows環境の場合、ウェブページで「ctrl+U」を押すとHTMLを表示できます。
以下の図は、ウェブサイトのHTMLファイルの例です。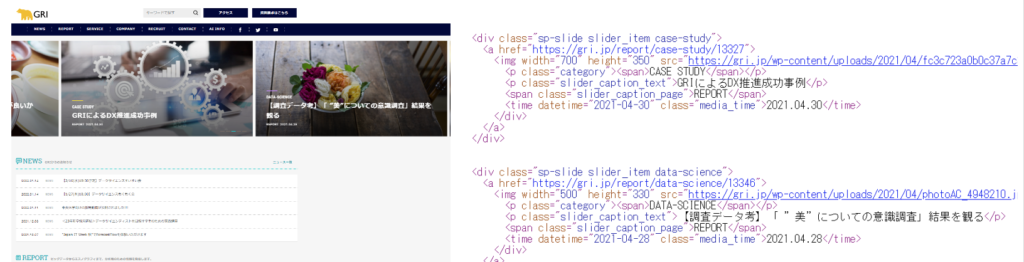
クローリングとスクレイピングとは
クローリングとスクレイピングのそれぞれの定義は以下となります。
- クローリング:ウェブサイトのHTMLファイルを取得する
- スクレイピング:HTMLファイルから必要な情報を取得する
クローリング、スクレイピングを行う方法は大きく分けて2通りあります。
①Pythonなどのプログラミング言語でライブラリなどを使ってコードを書く
Pythonには、クローリング・スクレイピングのライブラリやモジュールが揃っています。もっとも汎用的でほぼ全てのコードに使われるのは、requestとbeautifulsoupです。
②有償・無償の自動化ツールを活用する
以下は有名なツールの例です。
- Octoparse
- Web Scraper
- import.io
静的コンテンツと動的コンテンツ
ウェブサイト上からデータを取得する際には、静的コンテンツなのか、動的コンテンツなのかを見分ける必要があります。動的コンテンツは静的コンテンツよりも取得が難しいのです。
静的コンテンツとは、いつ・どこからアクセスしても同じウェブページが表示されるようなコンテンツです。こうなる理由は、ウェブサーバー上に常時設置されたHTMLファイルがそのまま返されて、表示される仕組みだからです。HTMLがサーバー管理者によって変更されない限り、必ず同じコンテンツを取得できるはずです。
これに対して、動的コンテンツである場合、アクセスした際のその時の状況によって異なるウェブページが表示される仕組みです。例えば、ウェブ検索では、ユーザーがクエリ文字列を入力すると、そのクエリ文字列を送信することでウェブサーバーに対してウェブページを要求します。そうすると、検索結果という形でウェブページを生成し表示します。動的コンテンツである場合、サーバーは要求(リクエスト)を受けた時に、その都度新たに、サーバーの上で動的にHTMLファイルを生成します。
動的コンテンツの取得は難しいが、ツールやライブラリを適切に活用することで取得可能である場合があります。PythonのライブラリSeleniumがその典型例です。
執筆担当:ヤン ジャクリン (分析官・講師)














