
回帰分析はシンプルで使い勝手がいい!
この記事の中で、売り上げデータに対して、回帰分析を適用する方法を紹介します。
売り上げデータはビジネスで非常によく扱われ、回帰分析もまた最も使われる分析手法の1つなので、ぜひ読者の皆さんも一緒に実践していきましょう。
本記事はG検定やDS検定を受験される方にとっても参考になると思います。
今回の演習の特徴は、プログラミングや難しい数式などを使わずに、Excel(およびそれに準ずる集計ソフト)で出来ることです。
実際には、ライセンスが必要なく無料で使えるGoogle Spreadsheet を用いた回帰分析の手順を示していきますが、ほぼ同じ操作が有料ソフトウェアであるExcelでもできます。よって、Excelユーザーの参考にもなりますのでご安心ください。
回帰分析をExcelで行う方法は大きく分けて3つあります。今回の記事で紹介するのは➁のやり方です。
- 回帰係数の公式を用いて、回帰係数(傾きと切片)を計算し、回帰直線の式$y=ax+b$を出す
- データをプロットしながら、Excelの関数を用いて回帰係数(傾きと切片)を求める
- Excelの回帰分析用の分析ツールを使う
実際①と②の本質は同じです。Excelの傾きと切片を計算する関数の使い方を兼ねて②にします。
あえてExcelの分析ツールを使わない理由は、回帰分析の概念(特にデータ点への直線の当てはまり具合)を操作しながら理解していただくためです。
(参考)回帰分析の背景知識
本記事では回帰分析の知識を細かく説明しませんが、参考として、弊社執筆の書籍からわかりやすいと思われる箇所を添付します。
ディープラーニングG検定(ジェネラリスト)最強の合格テキスト[明瞭解説+良質問題]
p96~97より

書籍リンク:最強のテキスト(G検定の緑本)
回帰分析を実践
課題:競合出版社の売り上げを予想
今回の課題設定は以下となります。
自社(出版社C)のPythonの書籍の今後の売れ行き、および同様なPythonの書籍の市場の状況を気にしています。Pythonやデータサイエンスの書籍が強い競合他社は出版社Aと出版社Bです。そこで、これまでの売り上げデータから回帰予測モデルを立てて、数ヶ月先の各社の売上を予測し比較することにしました。この予測結果をもとに、在庫の最適化やプロモーションの戦略を立てることにしています。
【具体的なタスク】
使用するデータはおよそ2.5年分の各出版社の代表的なPython書籍の月ごとの売り上げ冊数です。
- 月ごとの出版社A〜Cの売り上げの推移をグラフにしてください
- 可視化の結果から、出版社A〜C社にはどのような関数を当てはめるべきなのかを判断してください
- Excelの関数を活用して、出版社A〜Cのデータに合う関数の式を求めてください
- 求められた関数と実データを一緒にプロットしてください
- 将来の2022年10月の各社の売り上げを予測してください
- 今回の決定係数を計算してください
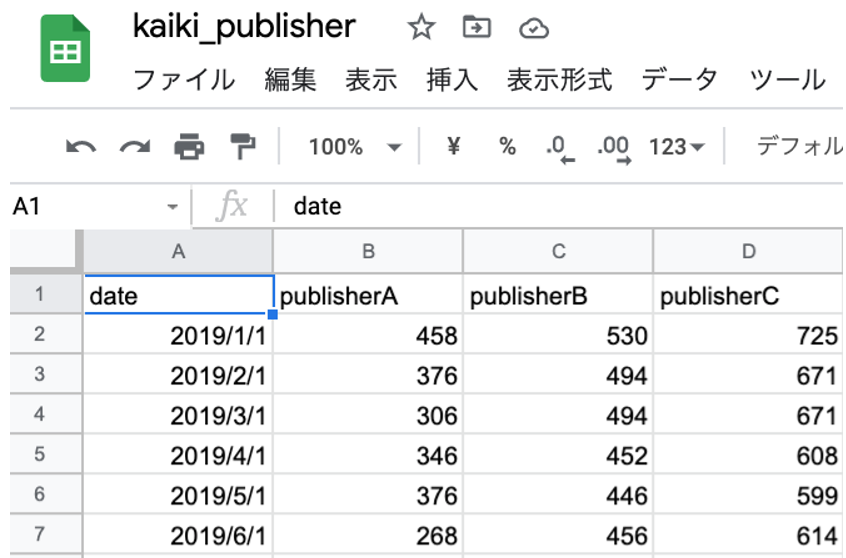
売り上げデータとして以下のような kaiki_publisher.csvを使います。
データの形式は以下のようになっています(最初の数行だけ表示)。
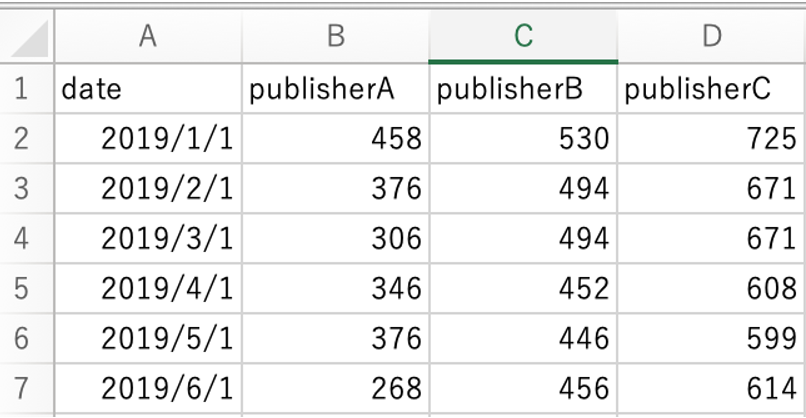
B〜D列にあるのは、毎月の1か月分の総売り上げ冊数ですが、A列の”date”には「その月の代表日付」として毎月の初日がYYYY/MM/DDで表示されます。Excelのデータ型の表示の都合上こうなっており、分析の結果には影響しません。
回帰分析を活用して売り上げ予測モデルを作る
ここから、Google Spreadsheet を用いた回帰分析の手順を示していきます。
データを読み込む
Google Spreadsheet で行う場合、まずスプレッドシートにデータをインポートします。メニューから「インポート」をクリックすると、GドライブまたはPCのローカルからデータファイルを取り込むウィンドウが出てきます。
今回はローカルからcsv形式の売り上げデータを取り込みます。
「今すぐ開く」をクリックすると、データが新しいスプレッドシート(新しいタブ)として現れます。
以降はこの新しいスプレッドシートの上で作業します。
実データをグラフにする
データを選択し「グラフ」ボタンを押します。
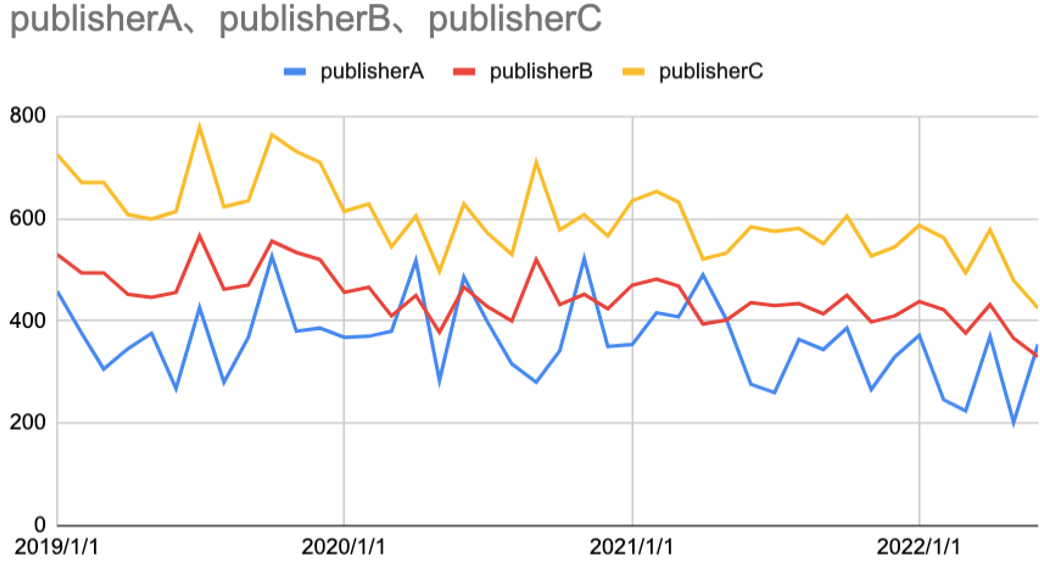
完成したグラフは以下となります。
データに当てはめる関数を決める
振れ幅が結構ある中で、競合の出版社Aは割と平坦で、出版社Bと自社(C)はやや右下がりの傾向を示します。各出版社に適した関数を以下のように決めました。
- 出版社A:定数関数
- 出版社B:1次関数
- 出版社C(自社):1次関数
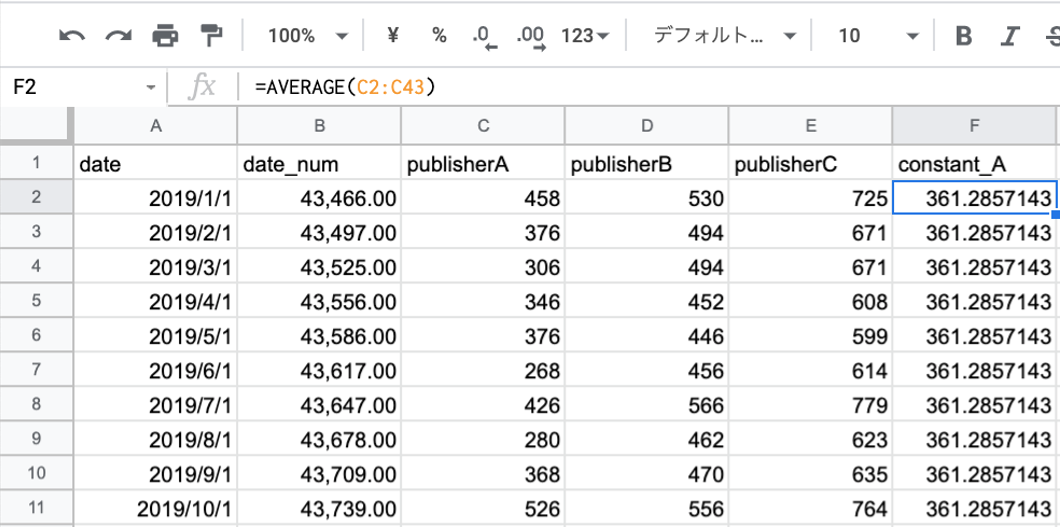
出版社Aのデータに当てはめる定数関数については、回帰係数には全データの平均値を使えることが知られています。
出版社BとCには単回帰分析(説明変数がdateの1つ)を使います。
まずは出版社Aに対する定数の係数を求めます。下図のように、C列の全データに対して、AVERAGE関数を使用することで求めることができます。
出版社Bと出版社Cに使う1次関数($y=ax+b$)なので、SLOPE関数とINTERCEPT関数を使って回帰係数(傾きと切片)の値を算出します。
下図が出版社Bの傾き(SLOPE関数)と切片(INTERCEPT関数)を求めている例です。

出版社Cの傾きと切片も全く同様に求めることができます。
回帰モデルを用いて予測値を出す
次に、求めた回帰係数を使ってB社とC社の売り上げの予測値を算出します。
その前に、回帰式の計算には日付型の値がそのままでは使えないので、Excelの関数を使う前に、A列のDateを「数値」型の表現に変換する必要があります。A列の隣に新たに列を挿入し、A列をコピーしたものを貼り付けし、表示形式を「数値」に変更します。
そうすると、数桁の実数が出てきます。馴染みのない謎の数値ですが、大丈夫です。これで回帰式がちゃんと求まります。
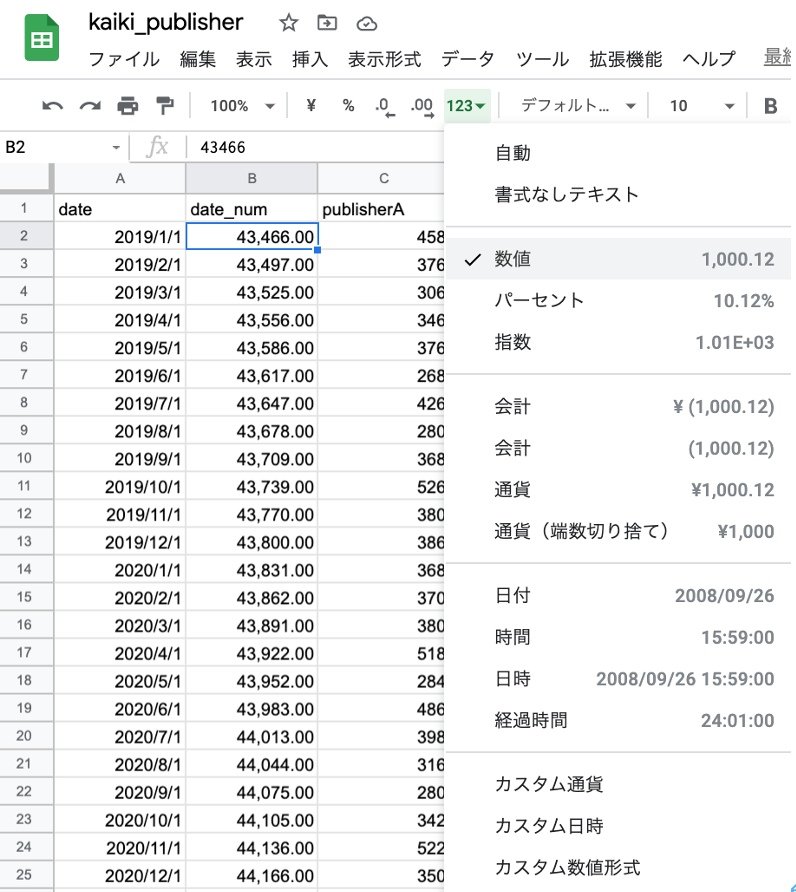
回帰係数を使って「予測値」を計算する際には、現在の列Bにある数値型のdate_num を使用します。
その計算の結果、および、実データと求められた回帰線を一緒にプロットしたものが下図となります。
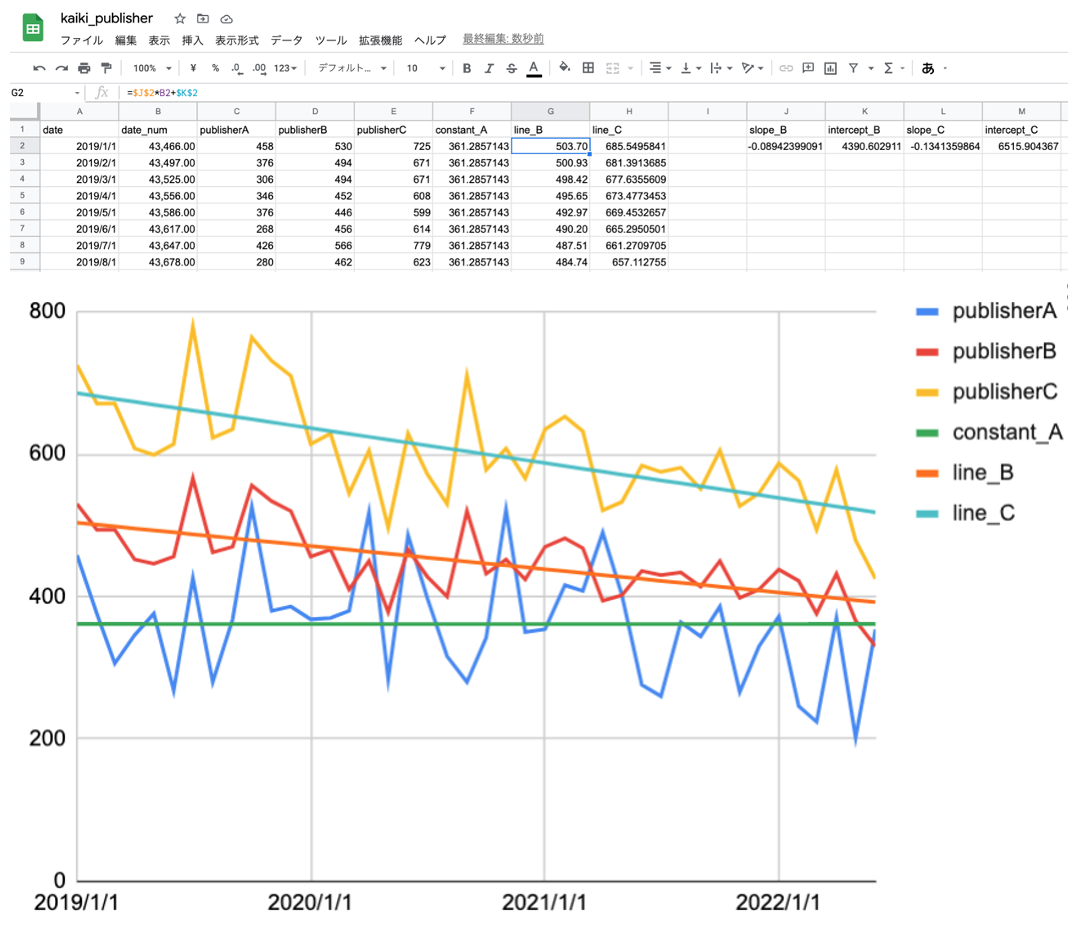
将来の売り上げを予測する
求められた回帰直線(学習済みモデル)を使って半年後の2022年10月の各出版社の売り上げを予測します。

結果、予測された2022年10月のPython書籍の売り上げは、出版社Aが361冊、出版社Bが381冊、出版社Cが502冊、となりました。最近低迷気味とはいえ、数ヶ月先はまだ競合よりは高い売り上げを獲得できていそうですね。その数ヶ月は売り上げをブーストする施策を考えるための時間です。
回帰モデルはどれくらいよかった?決定係数を算出
推定した回帰式がどの程度実データを再現しているかを評価するために、決定係数という指標を使うことが多いです。決定係数は下の式のように計算されます。
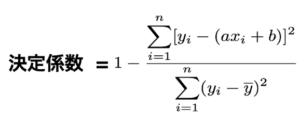
分子が(予測値の分散)、分母が(実測値の分散)という意味を持っています。
決定係数は0以上1以下の実数をとり、1に近いほど良いモデルといえます。決定係数が小さい場合、実測値が相関図の上でかなりばらついているのにもかかわらず、予測値は綺麗な一本線に近ければ、回帰モデルで上手くデータ点に当てはめているとは言えませんね。
では、最後に決定係数を計算しましょう。
先ほどのシートの右側に、決定係数を出版社Bと出版社Cについて計算するためのスペースに使います。あるいはこのシートを複製してから計算を行っても良いです。
まず、分子にある $y_i-(ax_i + b)$ の部分です。
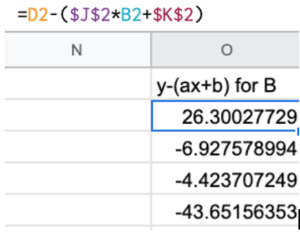
次にその2乗の計算します。
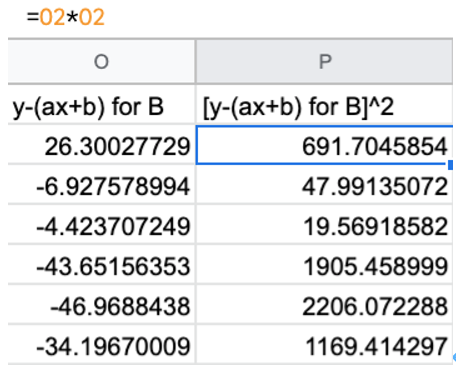
分母に使う $y_avg$(平均値)の計算です。
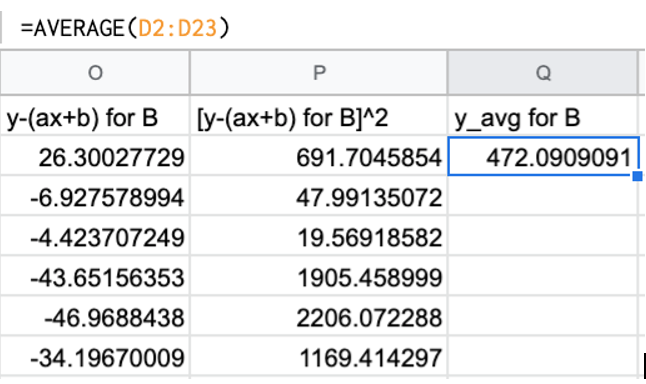
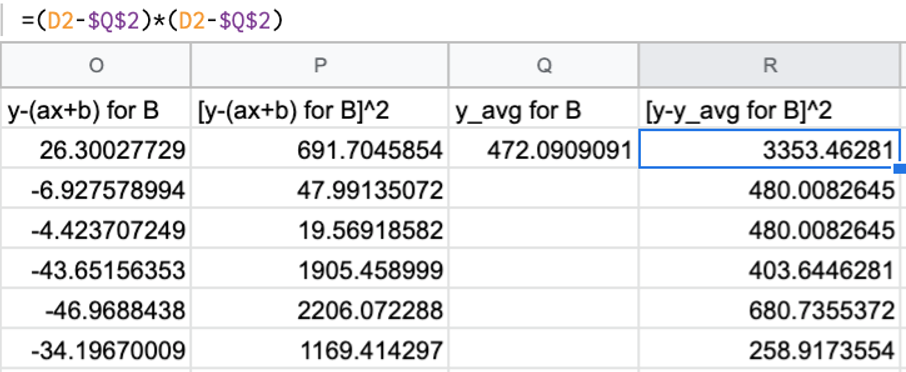
さらに、$y_i – y_avg$ の2乗です。
最後に全データで加え合わせて(Σ記号の部分)、決定係数の計算式に各部分を代入すると、決定係数が計算されます。
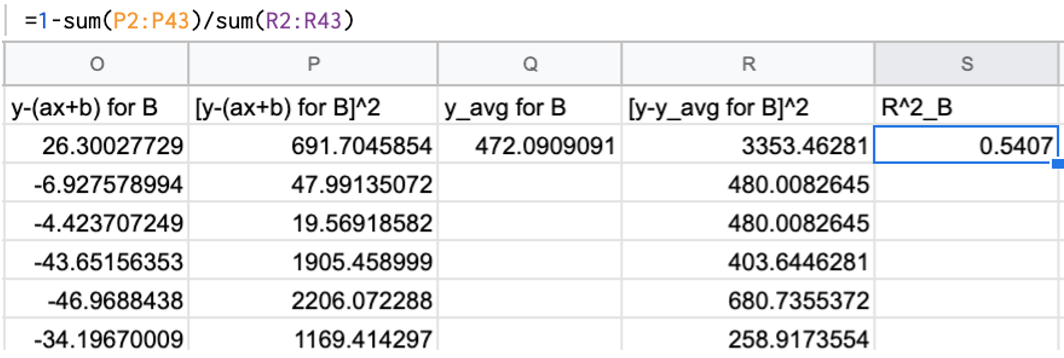
出版社Cについても同じように計算できます。今回のデータでは出版社Bと出版社Cの回帰線の当てはまり具合は等しく、決定係数が0.54程度でした。
決定係数の判断の目安
以前話した、決定係数は0が全く当てはまらない、1が完璧に当てはまることを思い出すと、0.54は「うんんん… 大丈夫かな…」と思われる方もいるかと思います。
今回は特に横軸が時間、つまり時系列データですので、ノイズが多く伴うのは当然です。実際、自然科学や株価など回帰分析がよく使われる分野では、決定係数0.5程度はよく見られます。上でデータをプロットした図を見ても、ノイズがそれなりに上下に降っている中で「全体的な傾向」を捉えられているように見えます。
仮に決定係数0.9のモデルが出来上がったら、もうそれだけで自然界が説明されてしまうことになり、この場合はむしろ過学習を疑うべきです。
あとは何を目的に回帰分析をしているかも考えましょう。
今回は売りゆきの大まかなトレンドを把握することで、自社(C)と他の出版社の数ヶ月先の大体の比較をしたいのが目的です。そうであれば、決定係数の数字だけではなく、直線をフィットした後の結果を見て、トレンドさえうまく捉えていれば、予測結果を「目安」として受け入れていいでしょう。
但し書き:
2次関数の回帰関数なのでLINEST関数を使って回帰係数を求めます。













