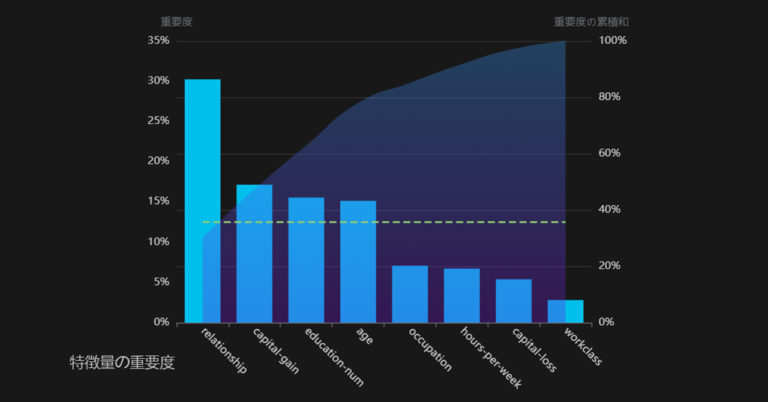
本記事の前編では、エンコーダ・デコーダ構造を持つ物体認識モデルについて紹介し、その上で具体的なモデルとして、FCN、SegNet、U-Netを取り上げました。後編では、さらに最先端なPSPNetとDeepLabについて話したいと思います。

物体検出・物体認識の研究開発に興味を持つ方やG検定を受験予定の方には、有用な内容になることを願っております。
以下のPSPNetとDeepLabはともに(前編のSegNetとU-Netと同じく)エンコーダとデコーダから構成されるセマンティックセグメンテーションの手法です。それぞれの特色に着目しましょう。
シーン画像とは
一般物体認識に関するタスクは複数あります。その中でも、シーン画像の認識タスク(シーン分割)は特に難しいです。
よりベーシックな物体認識タスクでは、「物体中心画像」(Object-centric image)を機械学習モデルへの入力とします。画像のほぼ中央に「注目物体」が1つ映っており、その注目物体のクラスカテゴリーを推測します。直接そのカテゴリを出力するのではなく、対象候補となる複数個の物体クラスから1つだけを選び出す問題に帰着します。
しかし、カメラで撮った写真や動画は必ずしも物体中心画像ではなく,シーン全体を撮影したシーン中心 (Scene-centric)の画像の方が多いです。この場合、2個以上の物体が場合によっては一部重なって映る可能性が高いです。
「シーン画像」の画像分類を行うことは,「シーン認識」または「シーン分割」や「シーン認識」と呼ばれます。シーン分割ではまず物体検出のアルゴリズムなどを用いて物体が存在する領域を切り出さないといけません。このとき、各物体の大きさがバラバラである場合は画像認識の精度が落ちることもあります。
このような困難があっても、それなりに高精度な認識を実現しているのが、PSPNetとDeepLabです。
下図に、複数の物体検出モデルによるシーン分割の結果を示します。

出典: https://ar5iv.labs.arxiv.org/html/1612.01105
PSPNet
PSPNet (Pyramid Scene Parsing Network) では、エンコーダとデコーダの間にPyramid Pooling Module(空間ピラミッドプーリング)を追加しているのが特徴です。
下図にPSPNetの模式図が示されています(出典:元論文)。エンコーダにはなResNet101の特徴抽出層を使用しています(図の(b))。Pyramid Pooling Moduleでは、エンコーダで抽出された特徴マップに対して、複数の解像度で最大プーリング(Max-pooling)を施します(図の(c))。これによって、複数のスケールで特徴マップを生成し、画像の大域的な情報から局所的な部分まで、広範囲にわたって情報を入手することができるようになります。続いて、デコーダで特徴マップに対してアップサンプリングを行い、シーン分割の結果を出力します。

出典:元論文: [Zhao et al., 2017] https://ar5iv.labs.arxiv.org/html/1612.01105
PSPNetは、複雑なシーン画像においても、高い解像度をもって複数物体の分離と検出を行う実力を示します。元論文中の実験ではPASCAL VOC 2012とCityscapes といったシーン分割の代表的なデータセットで一位を勝ち取っています。
DeepLab
DeepLabとは、Googleによって開発されたセマンティックセグメンテーションのモデルです。こちらも、エンコーダにはなResNetの特徴抽出層を使用しています。Dilation convolutionを行っていることが特徴です。
Dilation convolution(別名 Atrous convolution)とは、隙間の空いた歯抜けのフィルタを用いて畳み込む演算を行う手法です。日本語で言うと「膨張畳み込み構造」です。
下図のように、エンコーダの畳み込み層では、「歯抜け」のあるフィルタを用いて画像に対する、通常よりも「疎」な畳み込み演算を行います。この工夫により、一回のフィルタでカバーできる画像の面積が増えます。そうすると、プーリング操作を行わず、小さなフィルターサイズで長距離(広範囲)の計算を効率的に実行できます。

さらに、DeepLabでは、Dilation convolutionを畳み込み層のみならず、空間ピラミッドプーリングにも取り入れています(「2Dピラミッド膨張プーリング」)。DeepLab v3+ では、当時新たな発明である「分割可能畳み込み」も採用し、軽量化の特徴も加えられています。
※CNNの畳み込みをDepthwise(空間方向)とPointwise(チャネル方向)に分割することにより、パラメータ数を削減し、計算量を大幅に削減できます。当時は小型端末に使用されるMobileNetに使用されていました。
近年の物体認識では、高精度なセマンティックセグメンテーションとともに、計算の速度やリアルタイム性を重視されています。DeepLabv3+と並んで、PSPNetがセマンティックセグメンテーション用の標準的モデルとして普及しています。
執筆担当:ヤン ジャクリン (GRI 分析官・講師)