
本日は、
入社当初あまりにも分析するのが遅かったため、見兼ねた先輩社員が強い言葉にならないように非常に気を遣ってなんと言おうか迷った挙句
「YouはまだBigDataを扱う筋肉が足りないみたいだネ♪(爽やかスマイル)」
というお言葉を頂戴したことがある2年目分析官、岡部がお送りいたします。
「筋肉が、、、足りない、、、ッ!?」
それ以前にも日々筋トレという名の研鑽を続けていた私としては大変ショックを受けます。それ以来というもの、私はそれまでの甘えたメニューを見直し、基本に立ち返り、一日一千回、感謝のベンチプレス。そしてついに120kgを上げ、音を置き去りにするまでに成長いたしました。しかしどうやら、BigDataを扱う筋肉は胸筋ではなかったようで、いまだにBigDataを前にもたつくことがしばしばあります。
あれ、おかしいな、と
話が違うな、と
それじゃBigDataを扱う筋肉ってなんだったんだろう、、、と路頭に迷っていた僕に、先輩はひとかけらの魔法を僕に教えてくれました。
そう、Joblibという名の魔法です。
今日はみなさんにも特別にその魔法をお届けしようと思います。
ここだけの秘密ですからね?おばあちゃんにも内緒ですよ?
※参考記事
Python, Joblibでシンプルな並列処理(joblib.Parallel)_note.nkmk.me
PythonのJoblibによる並列計算について_Qiita
ちなみにこちらの記事の後続になります。最後の方で言ってた「次にやりたいこと」のうちの一つである「処理の並列化」です。べ、別に気が乗ったわけじゃないんだからねッ!

基本的なデータセットの準備やら、Prophetの使い方やらはこちらの記事を参照していただくとして、本記事ではデバイスごとの予測モデル作成の処理並列化にフォーカスします。また、joblibの使い方に関しても上で挙げた参考記事のように素晴らしいものがたくさんあるので、本記事では割愛させていただきます。(じゃあお前は何やってんだよ、この記事の存在価値はなんなんだよ、とか言わないでください。ケーススタディですケーススタディ!)
関数定義
joblibは関数ベースで並列化を行うので、まずは予測モデル作成の関数を作りましょう。ここではこんな感じ↓で関数を定義しました。
def main(deviceCategory, _df):
# 予測用インスタンス作成
m = Prophet()
# 予測モデルの作成
m.fit(_df)
# 予測用のデータフレーム準備
future = m.make_future_dataframe(periods=len(_df),freq='D')
future = future[future['ds']<pd.to_datetime('2018-01-01')]
# 予測実行
predict = m.predict(future)
# デバイスカテゴリの列を追加
predict['deviceCategory'] = deviceCategory
return predict
並列化せずに実行
まずはベンチマークとして並列化せずにそのままデバイスごとのループを回して処理した場合にかかる時間を確認しましょう。以前の記事同様、以下のようなコードを実行すると、下画像のような結果が得られます。
Wall time(プログラムの開始から終了までにかかった時間) を見ると、3つの予測モデルを作成して予測を実行するまでに、7.3秒かかっているようです。
%%time
# 並列化せずに実行
list_df = []
grouper = df.groupby('deviceCategory')
for deviceCategory, _df in grouper:
list_df.append(main(deviceCategory, _df))
df_predict = pd.concat(list_df)
df_predict.head()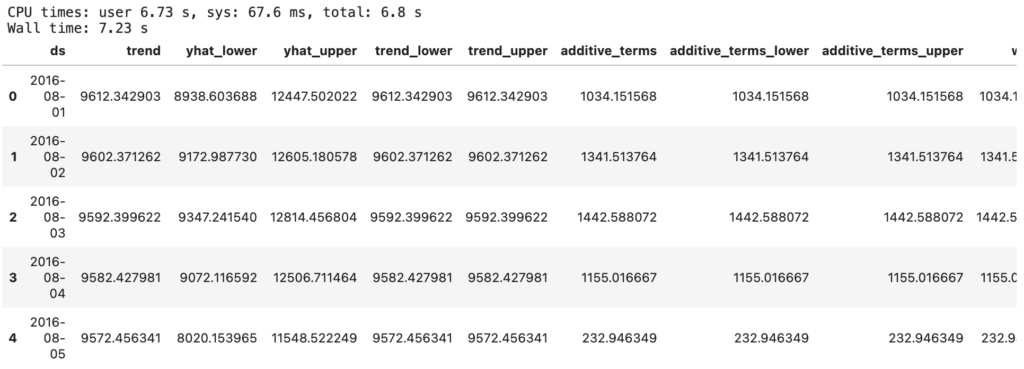
並列化して実行
それでは並列化して処理するとどうなるか?
並列化のためのコードを以下に記載します。デバイス数分だけのコアを使えばいいという考えからn_jobsは3としました。
結果は4.67秒と7割以下の時間で処理を完了することができたようです。
今回のケースでは予測モデルも3つしかなかったので7割程度の短縮にすぎませんでしたが、これが100個の予測モデルを作成するようなケースだとどうでしょう?コア数にも依存しますが、計算時間が10分の1になるようなことも楽勝であり得ます(ふわっとした言い方ですが、実際に案件でありました)。
まさに魔法、これぞBigDataを扱う筋肉のようなものでしょう。
%%time
# 並列化して実行
grouper = df.groupby('deviceCategory')
list_df = Parallel(n_jobs=3, verbose=3)(
[
delayed(main)(deviceCategory, _df)
for deviceCategory, _df in grouper
]
)
# デバイスごとのデータフレームをユニオン
df_predict = pd.concat(list_df)
df_predict.head()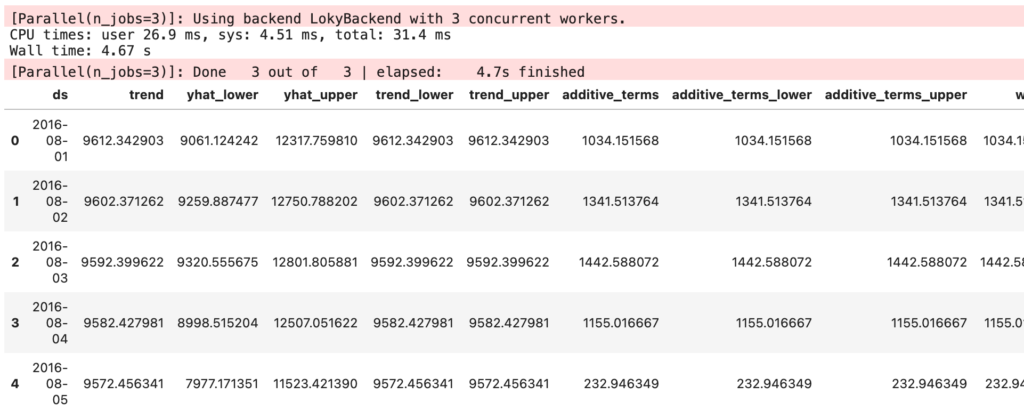
終わりに
処理を並列化して高速化する、というのは絶対的な正義であり、それ自体が顧客満足度に直結します。一例としていつも僕が思い浮かべるのが、黄色い看板を掲げた世界的に名だたる某ラーメン屋の存在です。彼らはその、独自のロット管理によってシステマティックに構築された提供フロー、席に着く前に注文を取るにも関わらず一部の狂いもない麺の茹で上げ時間、そして顧客自らがそこに参加し、食事プロセスすらシステムに組み込まれる美学、そういった処理の並列化を極限まで鍛え上げることで、よく知られているような熱狂的ファンを生み出すまでに至っているわけです。考えてもみてください、彼らが麺を一つ一つ茹でていたらどうでしょう?席についてから調理を始めていたら?間違いない、世界からまた一つ、たからものがこぼれ落ちていた。
そこで繰り広げられるやり取りは、まさに調教された顧客熱狂的なファンを持つコミュニティならではのもの。例えば、「ニンニク入れますか?」という一見何の変哲もない疑問文に対して回答される「ヤサイニンニクマシマシアブラカラメ」などといった謎の呪文。小さい頃学校の先生には「まず”はい”か”いいえ”で答えましょう」と教わったものですが、先生、”はい”か”いいえ”だけが答えじゃないんだぜ?
本論とは多少ずれてしまったかもしれませんが、本日は以上です。













