
統計学はデータサイエンスやデータ分析の根本にある学問分野です。勘や経験、ましてや一時のひらめきではなく、きちんと「客観的なデータに基づく科学的な分析によって意思決定をすべき」という認識をもたらしてくれた存在です。
データが社会の中で大量に発生し、それを有効活用するための研究開発が大きく進展したのはここ20年ほどです。一方で、何十年も前から統計学が学問分野の1つとして根付いています。ビッグデータ時代の到来によって、統計学にますます熱い目線が注がれるようになってきました。
今日、統計分析の他に、機械学習やBIツールなどデータ分析手法がいくつも普及しています。それらに先立って、データ分析は長年、統計学を駆使して行われてきました。また、他の分析手法による分析結果を解釈する際にも統計学を何らか役に立つことが多いです。
ちなみに、ここでいう「統計分析」は「統計学に基づいて考案された手法を用いた分析」を指しています。別の文献では「統計解析」と呼ばれることもあります。
ビッグデータの分析に関して、「機械学習」がよく取り上げられます。AIを専門としている所属の会社では日頃、機械学習を分析に用いたり、機械学習に関する講座も行っています。
統計分析と機械学習は両方ともデータ分析の手法であるところが共通です。
では、統計分析と機械学習の本質的な違いはどこにあるのでしょうか?
たまに「機械学習は統計学の進化版」、逆に、「数学ができない人は機械学習に走ってしまう」と聞きますが、これらは正しくありません!
機械学習と統計学の基本姿勢や目指すところが違うので、どちらが難しいなどの議論をしてもあまり意味がありません。
機械学習の手法や理論は、統計学に基づいた従来の分析手法の延長上に発展してきたのが事実です。しかし、機械学習と統計分析手法の本質的な違いはその戦略と目的にあります。
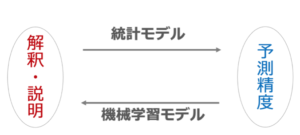

統計分析と機械学習のアプローチの違い
《統計分析の目的》
統計分析の目的は一般的にいうと、蓄積したデータに対して、その性質、特徴、傾向を明らかにすることを目指します。具体例としては、社員の収入の平均とばらつきの算出、全国学力統一試験の結果から偏差値の算出などが挙げられます。これは「記述統計学」です。また、集団全体(母集団)から有限サイズの観測データ(標本)をサンプリングし、標本から集団全体の状況を明らかにすることも統計分析でやっています。これは「推測統計学」です。
《機械学習の目的》
機械学習とは人工知能(AI)の1つの分野として発展してきました。機械学習では、蓄積されたデータに潜む特徴を見つけ、それらの特徴を軸にしながら機械学習のモデルを学習させます。学習のプロセスの中で汎用的な法則やパターンを自動的に見出す。学習のプロセスが完了した機械学習プログラムは学習済みモデルと呼びます。
学習済みモデルを使って、新たに取ってきた新しいデータに対して予測を行います。その理想的な姿は、答えが未知の新しいデータに対する予測に、学習済みモデルは満足できる予測精度をアウトプットできることです。
最初の機械学習プログラムを開発したアーサー・サミュエル氏の言葉によると、機械学習は「明示的にプログラムしなくても学習する能力をコンピュータに与える研究分野」と定義づけることができます。つまり、自動化を重視し、人間が予測の過程にあらわに関わらなくても、それなりに精度の高い予測結果を生み出せるのが機械学習の特徴です。
下図は、機械学習における「学習」と「予測」の工程を具体的に示したものです。
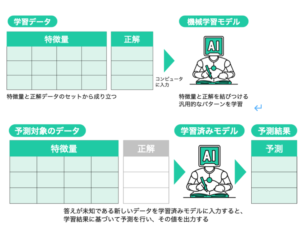
出典:ディープラーニングG検定(ジェネラリスト)最強の合格テキスト[明瞭解説+良質問題], https://www.sbcr.jp/product/4815611675/
統計学と機械学習の目的の共通的要素:蓄積されたデータから特徴を見つけ出す
目的の違うところ:統計学では解釈や仮定の正しさを検証することに力を入れているのに対して、機械学習では新たに入手するデータに対する予測・分析の精度を非常に重視している
大切にすることの違い 〜解釈性 vs 精度〜
《統計分析は解釈性を大切にする!》
統計学で大切にすることは、可視化や計算などの工夫を施すことで、データの性質、構造、傾向を解釈しやすくすることです。これを達成するために使われる統計分析のモデルも比較的シンプルに記述されているものことが多いです。少なくとも機械学習のアルゴリズムほど複雑ではないです。ここで「シンプル」というのは、モデルやそれを制御するパラメータの1つ1つの意味が人間にとって解釈しやすいことを指しています。例えば、線形回帰も、モデルの回帰係数がとてもわかりやすいですよね。また、全ての過程が統計学の理論に基づいて行われるため、分析のプロセスも結果も、しっかりとした科学的根拠をもって説明しやすいです。
統計学では「こういう関係性だと辻褄が合うのではないか」という仮説をあらかじめ立てて、そこにデータをあてはめて、仮説の妥当性を検証します。したがって、モデルの内部構造そのものに関心があり、全てにおいて論理的に説明できるようにならないといけません。
《機械学習は予測精度を大切にする!》
機械学習手法はとにかく高い予測精度を出せることに一筋です。これを達成するために、統計分析よりもずっと複雑かつ難解なアルゴリズムを用います。また、高い予測精度さえ出せれば、モデルの整合性をさほど気にしません。そういう意味で、様々なデータやモデルを自由に組み合わせての使用も許されます。
言い換えると、解釈しやすさや透明性を犠牲にしても、精度を少しでも上げていきたいというのが機械学習の姿勢です。
ただし、勘違いして欲しくないのは、機械学習ではどんなデータでもモデルに突っ込んでおけば高い精度を叩き出せる、というわけではないことです!現実は、精度をだすためには、アルゴリズムに適した形にデータを加工する、モデルのチューニングを行うなどの関門を通過しなければいけません。これらには専門的なスキルや知見が必要です。
機械学習の姿勢:モデルの整合性の証明が重視されず、問題があるのは精度が悪い時のみ!
しかしながら、近年ますます多くの機械学習アプリケーションを社会に実装してく中で、予測の経緯や結果をうまく説明できないことが「ブラックボックス問題」として問題視されています。
データ量の違い 〜ビッグデータ時代の今は?〜
《統計分析はデータ量がやや少なくても使える》
統計学の手法は、比較的少ないデータに対しても問題なく適用できる手法が多いです。コンピューターというものが存在しなかった昔の時代から、既に統計分析が使用されていました。当時はそもそも手動で収集・計算できるような有限のサンプルしか扱いませんでした。手計算で扱えるデータ量は多くても数百、数千件ほどです。数百件のデータがあれば、データの分布に関する仮定を満たせば、統計学に基づいた推論を行うことが可能です。
統計分析でも機械学習でも「データは多ければ多いほど良い」というのは事実です。しかし、統計学的アプローチを活用すれば「今手元で使えるデータから分かること」を引き出せます。これは、統計モデルの構造がシンプルであることとも関係しています。
《機械学習は大量なデータを扱うのが得意》
前述の通り、機械学習では大量なデータを用いた学習プロセスから汎用的な法則を抽出し、それに基づいて新しいデータに対して高精度な予測を目指しています。比較的大きなデータを扱うからこそ、機械学習はビッグデータの時代とともに勢力が増してきました。
実際にどれほどデータ量が必要かは、目的とアルゴリズムによって異なります。比較的シンプルな決定木系のモデルは数百件のデータでもモデルを構築できるケースがあります。一方で、注目されているディープラーニング技術のベースとなるアルゴリズムは、ニューラルネットワークであり、機械学習の中で最も複雑な部類に入ります。大規模な画像認識や自然言語処理のニューラルネットワークをゼロから訓練するためには、数百万件から数億件のデータまで必要です。
「データが多い方が、精度が上がりやすい」というのが機械学習の場合の大まかな感覚です。しかし、予測精度は決してデータの「量」だけで決まるわけではないです。データが少なすぎても問題ですが、多ければ多いほど必ず良いとは限りません。データが大量あっても、そこに変なバイアスが絡んでいると精度を悪化させてしまいます。
(まとめ)統計分析と機械学習の使い分け
では結局、統計分析と機械学習、どちらの方が好まれていますか?
条件と目的次第で使い分けることが重要と考えられています。
■統計分析を選ぶ場面
統計分析の過程と結果はともに解釈しやすいのに対し、機械学習はブラックボックスで解釈しにくいという指摘を受けています。したがって、上長や同僚に報告する、クライアントに説得力をもって提案したい時などは、統計学的なアプローチが有利かもしれません。
実際、「人間が解釈できる」という要請があるビジネスの場面ではいまだに、解釈しやすく、安心して使える統計学的手法を分析に採用することが多いです。
また、少量のデータしか使えないような状況でも、統計分析が選択されます。
■機械学習を選ぶ場面:
人間が手に負えない大量のデータを処理し、新しい発見を導き出すプロセスを高速に行えるのが機械学習のすごいところと言えます。 説明可能性や人間の介入が求められず、とりあえず予測精度と自動化・高速化を重視する場面で選ばれます。データ量を十分に準備できることも必要条件です。
機械学習アルゴリズムの複雑な構造の内部パラメータに大量のデータの情報を反映できるため、十分なデータを使用することができれば、シンプルな構造の統計的手法よりも高精度な予測・分析ができる可能性が高いです。
データ分析はもちろん、AIアプリケーションの作成にも機械学習の技術が活かされています。例えば、ウェブショップのレコメンドや広告最適化などの低リスク分野は、ロジックは複雑でも高精度さえ示されていれば使って問題ないことになります。
最後に…
ビッグデータの時代に、統計分析は不要になったと考えて良いのでしょうか。
=> よくないですね。
機械学習では、データ量さえ大きければバラつきは無視できるほど小さくなり、統計学のような誤差評価が免れそうで、一見理想的ですよね…
しかし、「ビッグデータの時代」でもそう甘くないです。大量なデータが蓄積されても、実際は欠陥だらけで、クレンジングを施した後に実際「使える」のは数百行も残っていないことだってあります。
担当者:ヤン・ジャクリン(分析官・講師)














