
明日はいよいよ 2021年第3回のG検定の日ですね。試験前に本当にやるべきことだけをしっかりやって、万全な状態で臨んでください。
講座を担当する私も、最新の情報を提供できるために明日は受験する予定です。試験後にまた皆で感想や振り返りを共有したいと思います。
皆さんのご健闘を祈っております。
本番で「力を出し切る」ことが肝心なので、今夜はとにかくよく寝て、試験開始(13:00)まで、頭を良い状態にしてください。
本番試験中はほとんど見る時間もなくても、不安のある分野に関しては、自作のメモやテキスト(に付箋でマークづけたもの!)を紙形式でPCの側におくと、心が安らいで、結局本番のパフォーマンスアップにつながります!
さて、本記事では近頃のG検定講座でいただいた質問の一部、及びその解答・解説をまとめてみました。多数の質問をいただいており、全て記事に反映できず申し訳ありません。
直前に軽く目を通すのに役に立てられたらと思います。
G検定講座Q&A公開
Q1: 勾配降下法と誤差逆伝播の違いは?
【質問】
勾配降下法と誤差逆伝播法の違い(使い分け?)が分かりません。それぞれ、最適なウェイトを導く方法論の違いという理解なのですが、勾配降下法を使う時と誤差逆伝播法を使い分け方が分かりません。教えていただきたいです。
【解説】
「使い分け」という概念がなくて、この2つはある意味で同じプロセスである意味で独立な概念として理解できます。
誤差逆伝播法は、単純に、出力層側から入力側に向かって誤差を考慮しながら重みの値を調整することです。勾配降下法は、損失関数の数学的な最小点に向かって、それを目標にしてパラメータを変更することです。この2つは「モデルの最適化」という同じプロセスを異なる側面から描写していると解釈してください。
Q2: 重み衝突問題について
【質問】
入力に関する場合は、入力重み衝突、出力に関する場合は、出力重み衝突と呼ぶと書かれていますが、具体的なイメージが湧きません。重み衝突自体の概念は、理解しているつもりですが、それがなぜ入力と出力時に問題になるのかが分かりません。隠れ層では問題にならないのでしょうか。
【解説】
RNNの時間軸に従っての展開と一般的なニューラルネットワークとしての重みの更新の間の矛盾として起きる問題が「重み衝突問題」です。言い換えると、RNNの再帰セルに入力された入力層および再帰セルから出力された信号が、長期的な特徴をもつのか短期的な特徴を持つのか分からない状態において、重みを大きくすべきか小さくすべきか決定できない問題です。
LSTMが導入される間に、RNNの再帰セルは単純なニューロンモデルが使用されていたために上記の問題で困っていました。さて、基本的に入力重み衝突も出力重み衝突も同様な考え方ですが、ネットワークの中で異なる位置にあるために、以下のようにあえて別々に説明しますと …入力重み衝突とは、「現時刻に入力された信号が重要なもの(保存すべき情報)なら重みを大きく、そうでなければ重みを小さくするが、今は重要でなくても将来役に立つ情報だったら重みはどうすべきか(大きくすべきか小さくすべきか)」という問題です。
出力重み衝突は、「現時刻に出力された信号が重要なものなら重みを大きく、そうでなければ小さくするが、今は有用でなくても将来有用な情報の場合は重みはどうすべきか」という問題です。
RNNでは、再帰セルの出力が再帰の重みを介して再帰セルの入力として再度伝わるので、「出力」でも「将来」を考慮しなければいけません。
Q3: 正則化について
【質問】
正則化は、NNなど回帰以外の機械学習手法にも使用」とありますが、決定木の手法でも使われるのでしょうか?
【解説】
機械学習は基本的にどのアルゴリズムも「損失関数」があります。よって正則化は決定木というか、どの機械学習でも使えなくはないです。ただし、手法によっては、正則化よりも効果的な過学習防止法があります。例えば、決定木の場合はランダムフォレストなどのアンサンブル学習を取り入れること、そして木の数などのハイパーパラメータをチューニングすることが一般的に有効です。
Q4: One-Hotベクトルについて
【質問】
予習でhttps://www.sbbit.jp/article/cont1/70672 を読んでいるのですが、下記の部分がよくわかりませんでした。数学のベクトルの箇所をもう少し解説いただけますでしょうか。
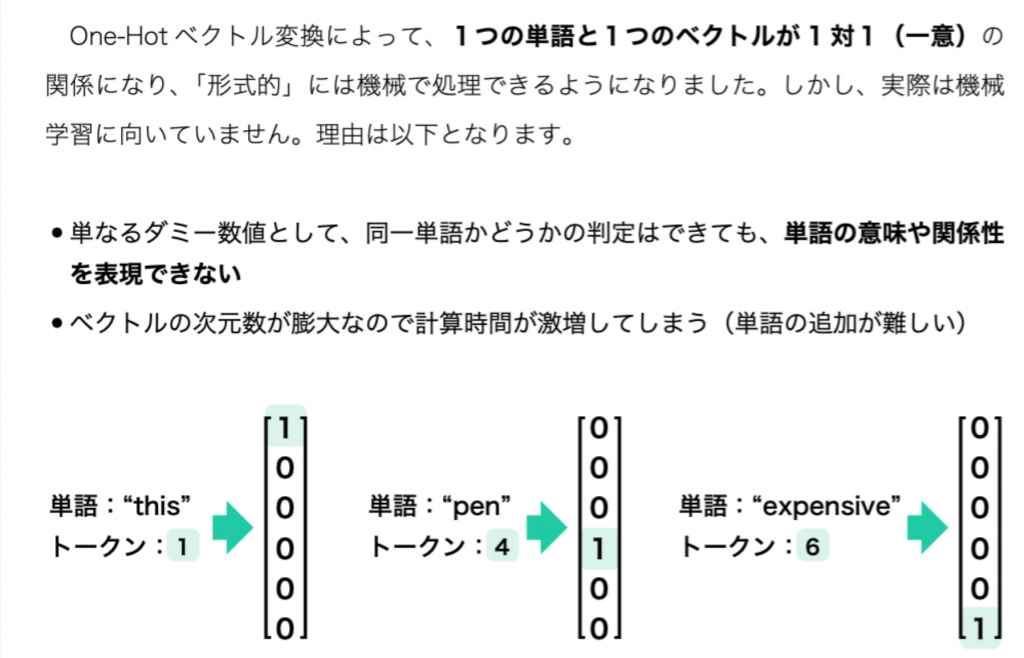
One-Hotベクトルとは文章内の単語の1つひとつに、(0,0……,0,1,0,……0,0)のような、全要素のうち1つだけが数値 1、残りはすべて数値 0 であるような長いベクトルを割り当てます。
【解説】
1つの文章にある、ユニーク(一意)な単語に1つ1つ番号(インデックス)を振って、ユニークな単語の種類の数だけ次元があるベクトル(通常はかなり長いベクトル)を用意し、1つの単語を1つのベクトルに一意に対応させます。ある単語の番号が五で、全部で20個のユニークな単語がある場合、長さ20のベクトルを用意し、上から5つ目のセルのみ1にし、残りの19は0となる(ほんとんどが0)のベクトルがその単語に対応します。
ベクトルは一単語あたり1つです。文章に20種類の単語があれば、長さ20のベクトルが20個あるイメージです。
例: I am a cat (単語4つ)
I (1,0,0,0)
am (0,1,0,0)
a (0,0,1,0)
cat (0,0,0,1)
以下参考:
(出典:https://www.sbcr.jp/product/4815611675/ )

Q5: 単語の数値化について
【質問】
「Bag-of-Words」と「単語分散表現」はともに数値ベクトルに変換することを思いますが、どのような違いがあるのでしょうか。
【解説】
Bag-of-words はプリミティブな数値化表現の1つです。機械学習を自然言語処理に適用する前から使われていました。単に1つの文章の中の各単語の現れる頻度を数値にして並べているだけの表現体系です。それに対して、特殊な変換行列を用いて、単語の意味(の近さ)を表せる数値ベクトルにしているのが単語埋め込みモデルです。
Q6: 特徴量エンジニアリングについて
【質問】
特徴量エンジニアリングが必要なのは、教師あり学習の「学習データ作成」のために必要なのでしょうか。もしくは一言で「特徴量エンジニアリング」といっても、教師あり/なしや手法に応じて、変わってくる(特徴量の選択など)ということでしょうか?
【解説】
まず簡単に答えると、特徴量とは、対象となるデータの特徴を数値にして表したもので、予測モデルを立てるときにこれを手掛かりにしています。その準備の本質は教師あり・なしが本質ではないです。
教師あり・なしではなく、その時にやりたいタスクとデータの性質で判断して、特徴量エンジニアリングを、予測精度を高めるために実施します。
●予測変数として採用する列を選別する
●データに前処理を施し、予測に効果的な形に加工する
以上のことは構造化データでも、画像のような非構造化データでもある程度の「データ前処理」が必要と考えるのが一般です。
Q7: 特徴量エンジニアリングについて
【質問】
ニューラルネットワークの分類
手法(活性化関数の種類?)によって、回帰のときもあれば、分類のときもあるということになるでしょうか?
【解説】
ニューラルネットワークは、分類に使うこともありますし、回帰に使うこともあります。どうしても画像分類など、「分類」の方が印象が強くなりますが。
活性化関数によるかどうかですが、特徴量を抽出するのに使われる隠れ層の活性化関数は特に分類か回帰かに関係ないです。一方で出力層にある(別の意味・役割)の活性化関数は、分類問題の場合は、softmax関数、回帰の場合はロジスティク回帰関数など、使い分けがあります。活性化関数が分類or回帰ではなく、考え方は逆ですね。分類をしたいのか回帰をしたいのかによって出力層での関数を選びます。
上記でシェアしたQ&Aはもちろん、2021年の試験だけではなく、データサイエンスの基礎に関する内容なので、いつでも役に立つと思います。
それでは、今回も読んでいただき、ありがとうございました。
記事担当:ヤン ジャクリン (分析官・講師)












