
大量のアクセスがきてもサーバーが落ちないこと。これは大事なデータを扱うサービスの重要な要素であったりします。
そんなことの無いようにリリース前に負荷テストをしようぜということになりました。
今回はpythonのlocustという負荷テストツールを使ったメモです。
誰が使っている?

引用:locustページより
locustの公式ページにはGoogle, mozilla, amazonなどが使っているようです。
インストール
# pipから
pip install locust
※Dockerでも公式イメージがあるので、その場合はローカル環境へのインストールは不要です。
# versionの確認 locust -V # locust 1.5.2
私の環境では1.5.2のバージョンになります。
コード
公式のTutorialから。
# locustfile.py import time from locust import HttpUser, task, between class QuickstartUser(HttpUser): wait_time = between(1, 2.5) # 1ユーザーのページ滞在秒数の範囲 @task def hello_world(self): self.client.get("/hello") self.client.get("/world") @task(3) # 数字はtaskの重み def view_items(self): for item_id in range(10): self.client.get(f"/item?id={item_id}", name="/item") time.sleep(1) def on_start(self): self.client.post("/login", json={"username":"foo", "password":"bar"})
- 実行後、各メソッドはランダムにリクエストされる
- 重み task(3)と入れることで、hello_worldメソッドよりもリクエストが単純に3倍呼ばれる率が高くなる
- on_startはユーザーのリクエストの最初に行われるメソッド. 上記はon_startでページログインを行った後、hello_world, view_itemsそれぞれのメソッドを実行する
実行
locust -f locustfile.py
※Dockerの場合
docker run -p 8089:8089 -v $PWD:/locust locustio/locust -f locustfile.py

ではブラウザからhttp://0.0.0.0:8089にアクセスしてみます。
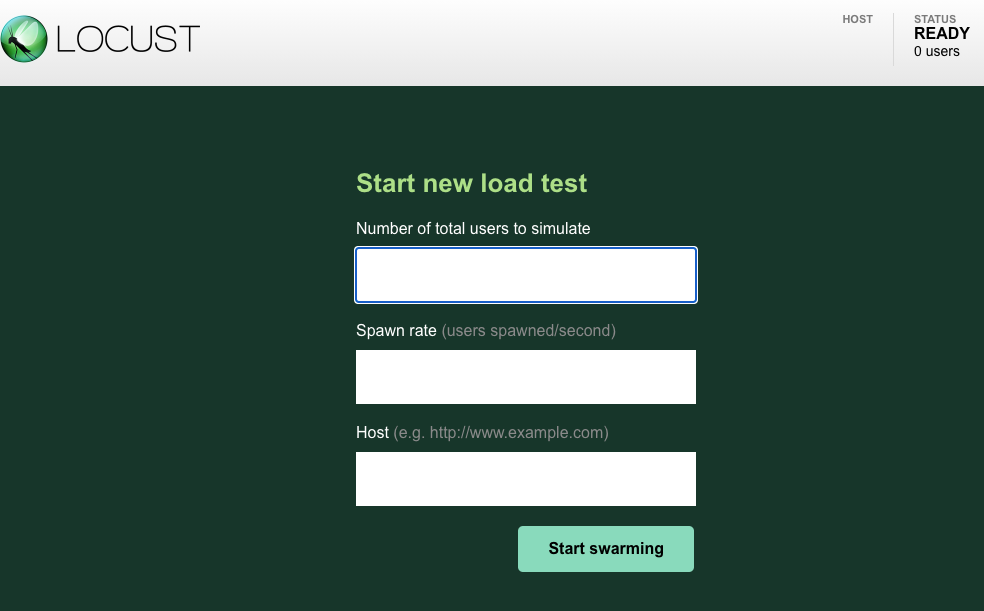
- Number of total users to simulate
- 最大の同時接続数
- Spawn rate
- 1秒あたり何ユーザー増やしていくか (最初から最大数にしたい場合は”Number of total users to simulate”と同じ数字にすればよい)
- Host
- リクエストを投げるドメイン名 (例: https://www.google.com)
イメージ図
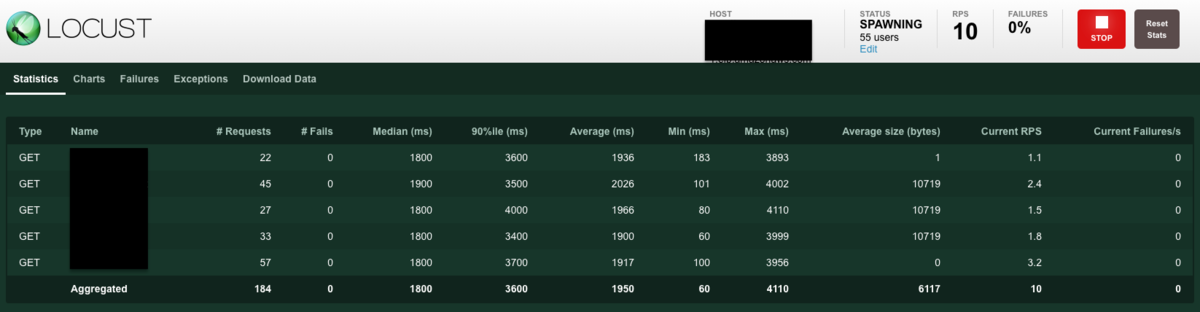
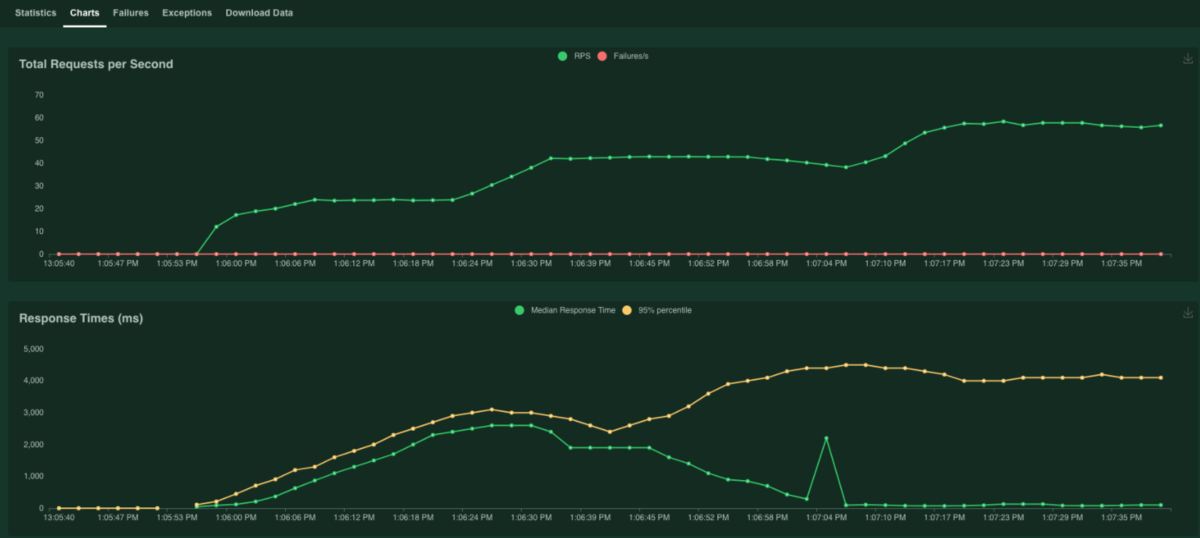
リアルタイムで動作確認ができます。
また、プロセスを止めた時はコンソールにサマリー結果を出力してくれます。
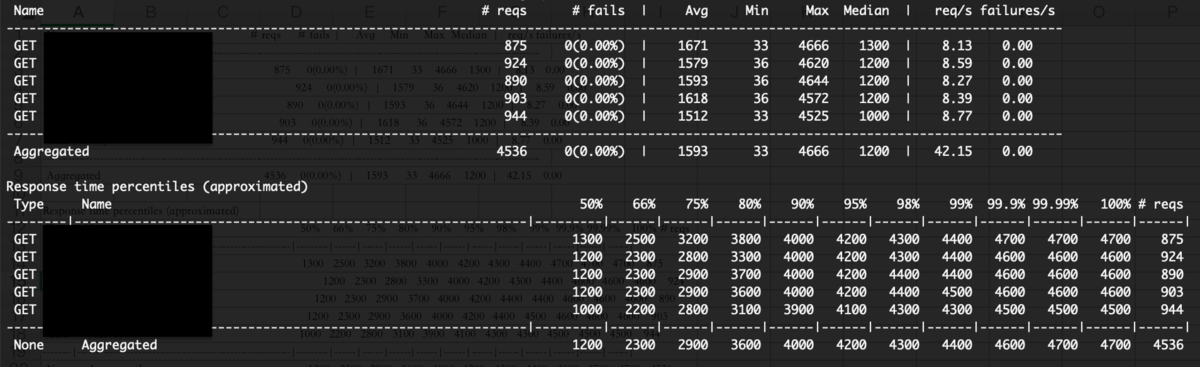
図ではきれいな数字ですが、実際にはステータスが500(サーバーダウン)になる閾値を見つけてインスタンス数やスペックの調整をしたりしました。
参考
Locust Documentation — Locust 1.5.3 documentation
負荷テストツール、Locustで遊ぶ
higashi kunimitsu














