大規模なオープン画像データが必要になったので調査してみました。
ImageNet
オープンデータの中で特に有名なデータセットです。
かなり細分化されており、大量のクラスが存在しています。
WordNetに紐づけられており、階層構造になっているので、目的の画像が探しやすくなっています。
Poppyを選択してみました。Poppyだけで16クラスも持っています。
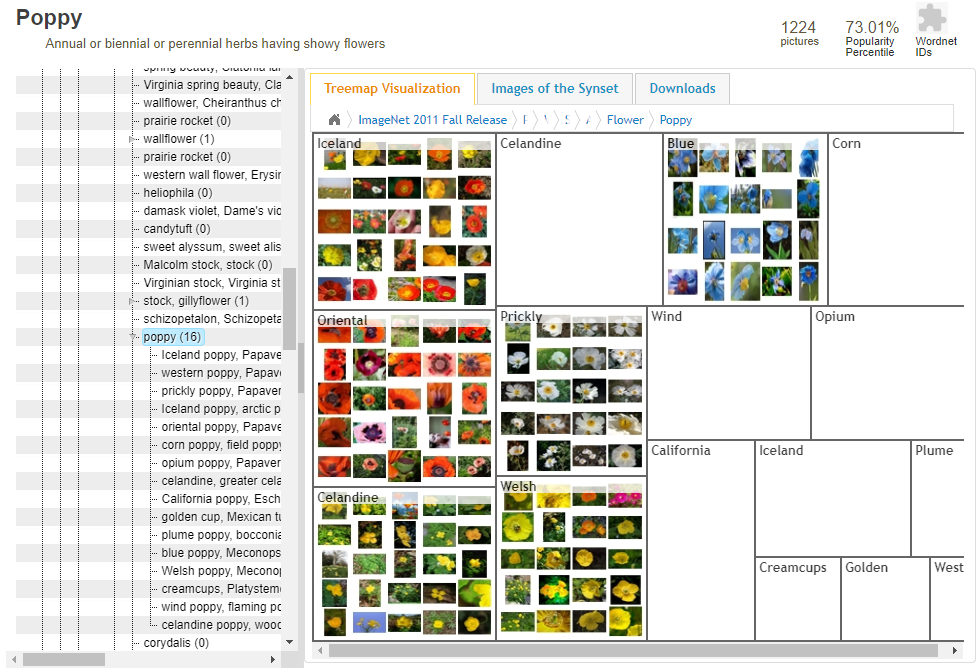
ランダムにクラスを選んで、アノテーション情報に関しても確認してみます。
体感的には1/3くらいがバウンディングボックスの情報を持っているようです。
Open Images Dataset
Googleが出している画像の大規模データセット。クラス数はそこまで多くはないようです。
Appleを選択してみます。
TypeをDetectionにするとこんな感じ。バウンディングボックス付きの画像が表示されました。
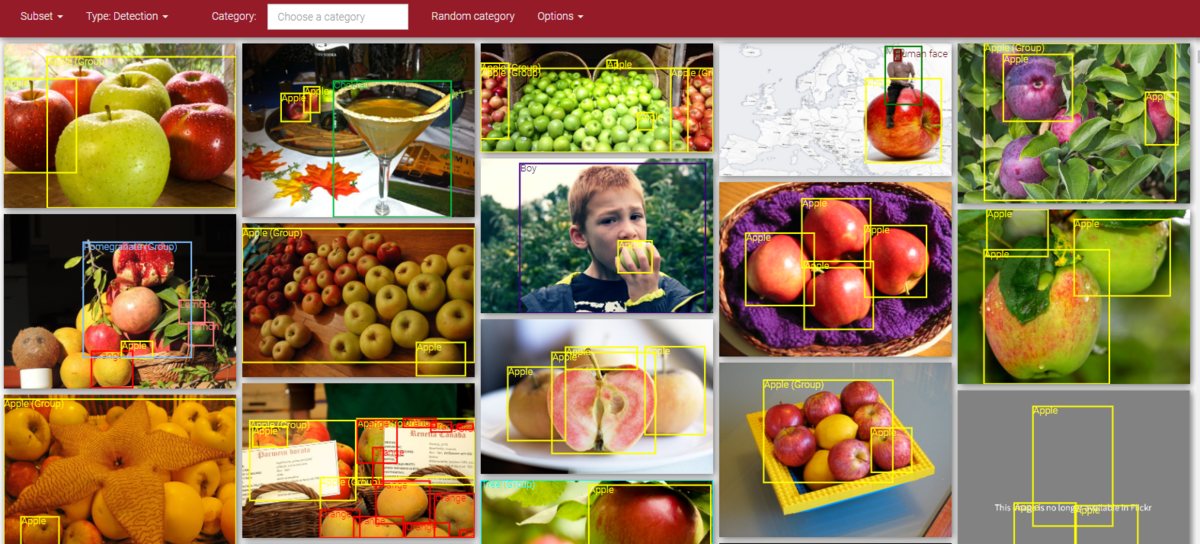
個別では認識できていないものも多そうですが、集合体だと認識されたものに対してはApple(Group)というタグがつけられているようです。
TypeをSegmentationに変更してみます。リンゴの領域が塗りつぶされた画像が出てきました。
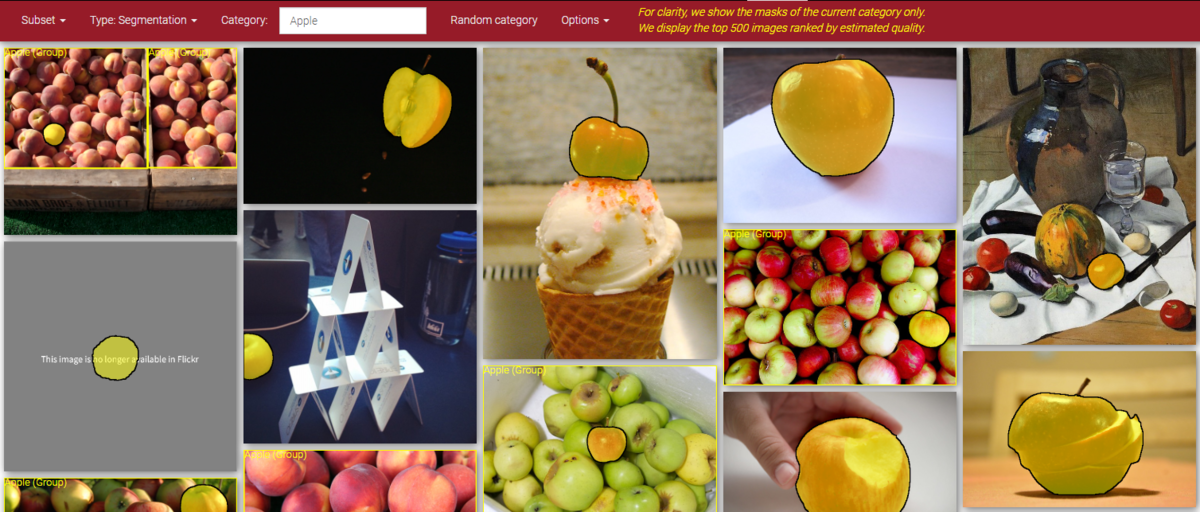
個別で識別できているもののみがSegmentされているようです。
COCO dataset
豊富なアノテーションが特徴のデータセットです。
chairとwine glassを選択して画像を検索してみます。
chairとwine glassの両方が含まれている画像が数多くでてきました。
画像から抽出されたものが画像の上に表示されています。
さらに画像に対するCaptionも生成してくれています。

もう一枚見てみます。

奥にいる人などはSegmentされていないようですが、手前にあるものは高い精度でSegmentされています。
おわりに
今回は登録なしで気軽にデータを確認できる3つのデータセットを調査しました。
今回紹介したもの以外にも動物の画像だけのものや工業製品の画像だけのものなど条件を絞ったデータセットは数多くありそうです。