
Google Drive 上に保管されている画像に対してPythonのパッケージ pyocr を使ってOCR処理を施し、抽出された文字をcsvに出力するという一連のことをやってみました。
Google Colaboratory(GoogleColab) で走らせたJupyter Notebook のコードを直接お見せしながら流れを見せていきたいと思います。
環境の準備
まず、必要なパッケージをインストールします。
こちらを参考にしました。https://www.teamxeppet.com/colab-pyocr/
今回は日本語が書いてある画像から日本語テキスト(英語が混ざってもいい)を抽出しますので ocr-jpn の方ですね。
このインストールがうまく行けば、”Successfully installed pyocr-0.8″ などのメッセージが実行結果の最後に出るはずです。
つぎに、tesseract認識できる言語の種類を確認します。「jpn」が出力されているのを確認したので、今回の日本語が書かれた画像への使用にはOKですね。

今度は、pyocrに必要なモジュールをインポートします。
ここではpyocrと画像を読み込むために、画像処理のモジュールPIL(PythonImagingLibrary)のうち、Imageモジュールをインポートします。
その次のセルでは、pyocrが利用可能であることを一応確認します。tesseractが正常にインストールされているようですね。
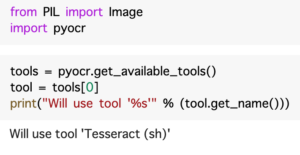
Gドライブのセットアップ
今回はGoogleColabを使い、Gドライブ上の画像にアクセスしてテキスト変換、つまり全てのプロセスをGoogleの環境の中で済ませたいです。
以下のドライブを「マウント」するコードを実行すると、アカウントの選択画面に遷移するためのリンクが出ます。これに従い以下のようなページに移ります。ここでドライブをマウントしたいアカウントをクリックします。
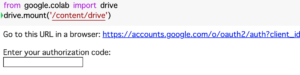

上記がうまくいくと、以下の “Mounted at /content/drive” が表示されるはずです。

早速、画像にOCRを適用してみる
sample1.png という画像ファイルを認識させてみましょう。
sample1はこんな画像です。吹き出しの中に言葉があり、画像の中のキャラクタには名前がついています。

コードとその結果はこのようになりました。

これを観察してわかったのは …
吹き出しの囲みがあるゆえに、その中の文字に「飛び」が出てきてしまった。
つぎにもう少しシンプルな、符号や図がほとんどなく文字の一段落だけの図 “sample2.png” です。

コードとその結果はこのようになりました。今回は問題なくできているように見えますね。

ちなみに、より精度良く取り出してみたい場合は、「tesseract_layout=」の値を変更(デフォルトは3で、例えば6に)することを試してもいいかもしれません。
参考:https://github.com/tesseract-ocr/tessdoc/blob/master/ImproveQuality.md#page-segmentation-method
Gドライブ上の画像を一括にテキストに変換
つぎに、ドライブにある6個の画像に対して一括変換をやります。(もちろん実用上は数百とかもっとたくさん画像を入れますが)
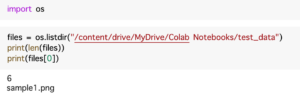
ループ処理で回して、画像のファイル名、及びOCRを施した後のテキストを2次元のリストに格納します。

OCRで抽出したテキストをCSVに出力
日頃の習慣として、何かの手段で抽出したデータをPandasのDataFrameにまずは格納します。その方が気持ちが良くて、csvやexcelに格納しやすいだけです。
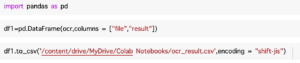
ということで、結果をDataFrameに格納し、csvに出力しているコードは以下です。
ダウンロードしたcsvをExcelで開くと文字化けしたので、エンコードを別途指定しました。
Summary(考察)
ここでデモに使った以外の画像にこのコードを施した結果を観察すると以下に気づいています。網羅的ではないですが、OCR技術の課題のイメージになれればと思います。












