
データ可視化の意義
データを分析するプロセスの中で、データを可視化することが重要なステップの1つです。
可視化するというのは、分析対象のデータに対してグラフ、プロットを作ることです。
なぜ、可視化するかというと、「見える化」することによって、例えば、以下のことを概観できるからです。
- データの全体像、全体的な傾向
- 複数の変数の間の相関関係
- 異常値、外れ値、欠損値の有無
- 時系列的・季節的な変動
これらの観察結果は、どのようにデータの前処理を行うべきか、特徴量エンジニアリングの方針、機械学習などの分析手法を使うのか、を判断するための不可欠な材料になります。
データを可視化する手段はいろいろあります。実はデータを可視化することに特化したBIツールがあります。BIツールを使って可視化分析を行います。一方で、今回は、Python を用いてデータ分析する際に使用する代表的な機能群を2つ紹介します。1つはmatplotlibの中のモジュールpyplot。もう1つはseabornです。
これらの可視化ライブラリを他のPythonの分析用ライブラリと合わせて使うと、Jupyter Notebook の上で「インタラクティブ」なデータ可視化が出来ます。つまり、データのプロットを作ることと、分析をすることを交互に行うことができるという意味です。データを見える化することによって、新しい発見が得られて、それに基づいてデータに対して適切な処理を行い、その変換を施した後のデータを再び見える化して確認するというプロセスを通じて、データ処理を最適化することができます。
matplotlib
Pythonの可視化用ライブラリの中で、最も歴史的に古いのは、matplotlibです。カスタマイズ性が高く、豊富な種類のプロットを作成できることでとても使いやすいです。
※データサイエンスのもう1つの標準言語R言語に置いてmatplotlibに相当するライブラリ(counterpart)は ggplot2 です。
Matplotlibの公式チュートリアル:https://matplotlib.org/3.3.3/tutorials/index.html
Seaborn
Seaborn はワンランク上のおしゃれなグラフを作れることで人気です。ところで、実はseabornはmatplotlib のラッパです。つまり、SeabornライブラリはMatplotlibライブラリの上に構築されています。個人差はありますが、一般的にmatplotlibに比べて、seabornの方が書式が直感的で簡単めです。本当の初心者はseabornから学ぶと良いという意見の方もいますが、私は個人的に、デファクトスタンダードのmatplotlibを先に習得することを勧めます。
Seabornの公式チュートリアル:https://seaborn.pydata.org/tutorial.html
データ種別によってグラフタイプを選ぶ
折れ線グラフ
- データの増減を見るため
- 横軸には連続値をとることが多い(日付、時間、量など)
https://matplotlib.org/api/_as_gen/matplotlib.pyplot.plot.html?highlight=plot#matplotlib.pyplot.plot
棒グラフ
- 群同士の比較をするため
- 横軸にはカテゴリなどの離散値を用いることが多い。
- 棒の高さでデータの大小を表す(縦横が逆の場合もあり)
https://matplotlib.org/api/_as_gen/matplotlib.pyplot.bar.html
ヒストグラム
- 連続値データの分布を観察するため
- 横軸にデータの階級(等間隔に区切られたビン)
- 縦軸にその階級に該当するデータの出現頻度数をプロット
https://matplotlib.org/api/_as_gen/matplotlib.pyplot.hist.html
散布図
- 両者の間の関係を調べるため
- 縦軸と横軸にそれぞれ別の量(連続値が多い)
https://matplotlib.org/api/_as_gen/matplotlib.pyplot.scatter.html
MatplotlibとSeabornを使ってみましょう
今回は Jupyter Notebook 上での コーディングの違いと可視化結果の違いについて見てみましょう。
(注)どちらのライブラリも詳細設定を頑張れば、見た目同じようなグラフを作れますが、今回はそのような非現実な設定をせずに、基本的なコーディングでグラフを作ったときの見た目の違いを比較したいと思います。
どちらのライブラリも、Anaconda ディストリビューションでPythonを使用する際には、既にインストールされている状態です。
Matplotlib のプロットを作る機能はほとんど全て、pyplot というモジュールに含まれています。
通常は、以下のようなコードでpyplot を呼び出します。慣習的にpltとエイリアスされます。

Matplotlibを用いたプロットの基本的な作業手順は以下です。この書式はSeabornでもかなり似ています。
①キャンバスの作成: fig = plt.figure(figsize)
②描画領域の設定: ax = fig.add_subplot(nrows, ncols, index)
③データ点を指定して描画: ax.plot(x, y) など
Seabornは通常、以下のようなコードで呼び出します。慣習的にsnsとエイリアスされます。

早速、簡単な折れ線グラフを作ります。
まず必要なライブラリをimportします。サンプルデータを生成するためにnumpyも呼び込みます。

ここに見えている%matplotlibでバックエンドを変更できる「マジックコマンド」です。これを入れると、プロットがJupyter Notebook の中で効率的に表示されます。
- %matplotlib inline: グラフ固定
- %matplotlib notebook: グラフを移動・サイズ変更などのさらに高度な機能を使えます(Notebookがやや重くなります)
Matplotlibのコードは以下です。

実行すると、以下の折れ線グラフが現れます。
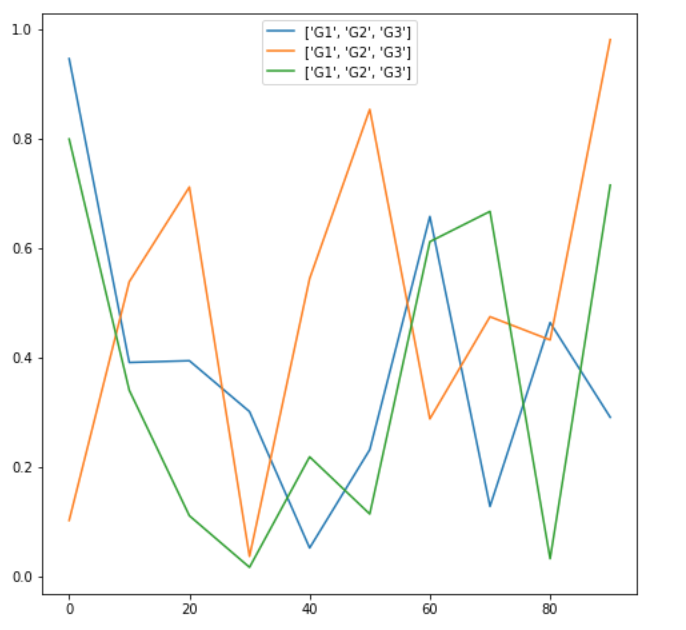
Seabornのコードは以下です。

実行すると、以下の折れ線グラフが現れます。
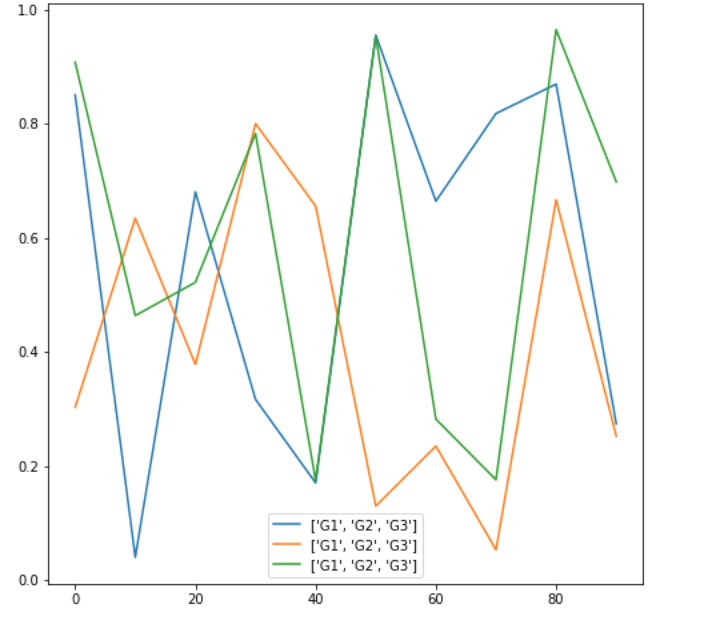
2つの結果を比べるとわかるように、装飾の少ない、シンプルなプロットを描く場合は、Matplotlibを使ってもSeabornを使っても、あまり違いはありません。
今度はSeabornを使って、もう少し高度な可視化分析を行った場合の結果を載せます(上流の分析コードを省略)。これらは、Kaggle の”heart disease” データセットを用いて、診察結果の変数と心臓疾患の関連性を分析する中で可視化したものです。
Heart Disease Dataset | Kaggle
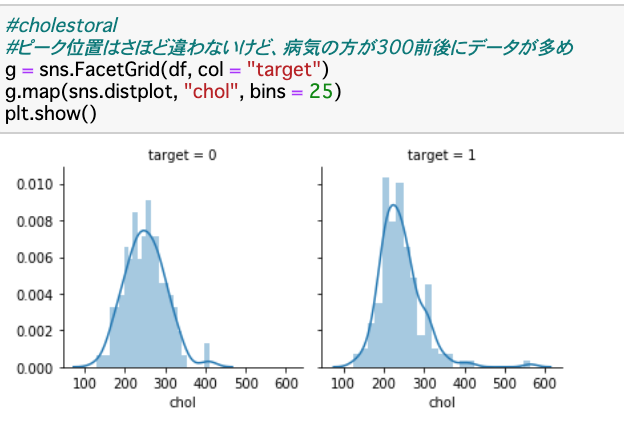
ヒストグラム

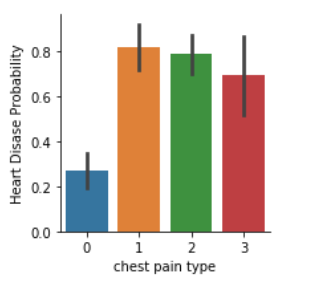
棒グラフ
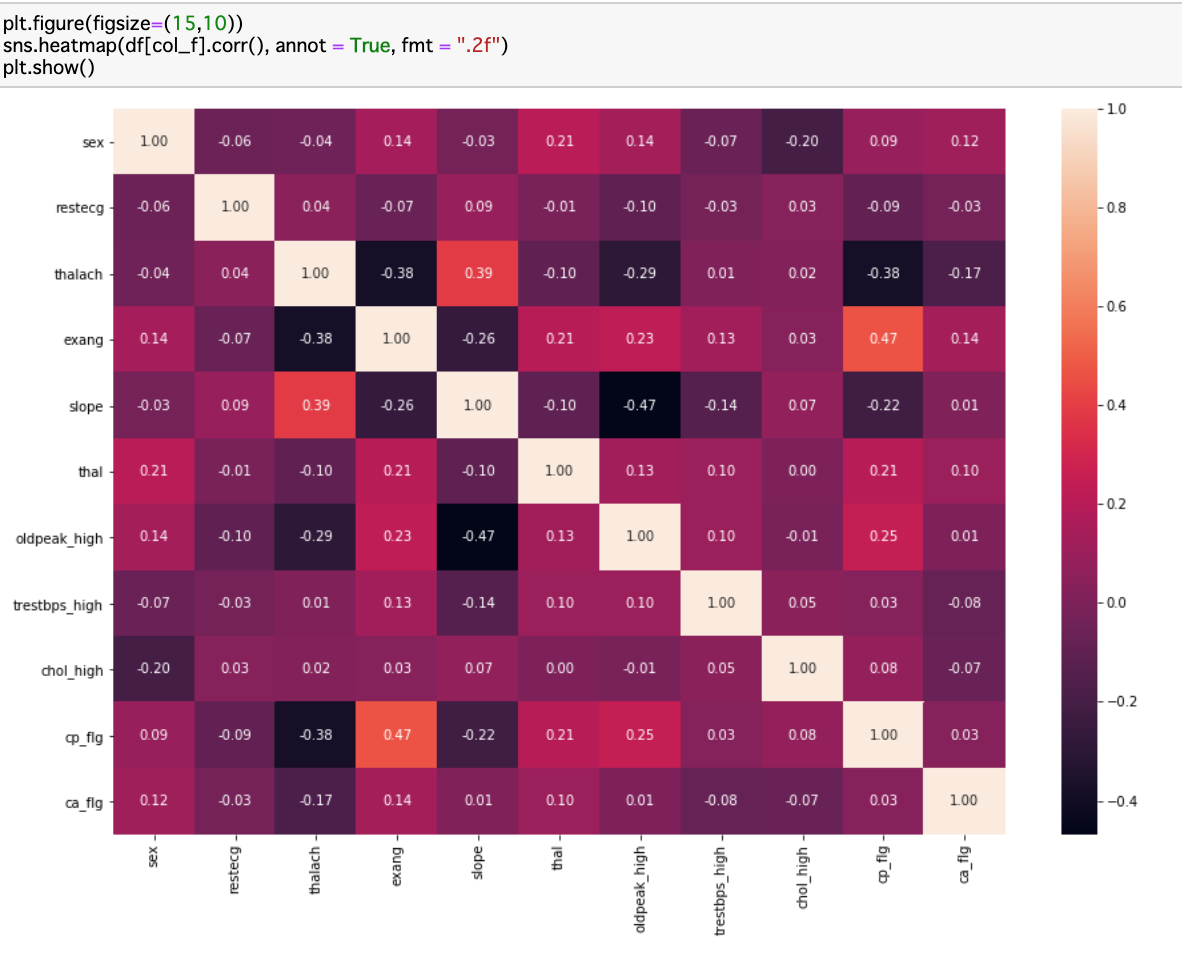
一番最初に作ったシンプルな折れ線グラフよりも、Seabornの本領が発揮できています。
皆さんも是非サンプルデータ、もしくは手元のデータでMatplotlibとSeabornを用いて、様々なプロットを作って楽しんでみてください。
担当者
分析官・講師
ヤン・ジャクリン















