大規模自然言語処理モデル(LLM)の基盤技術であるTransformerは多数のAttentionで構成されています。
Attentionの重みの計算にはQuery(クエリ)・Key(キー)・Value(バリュー) という3種類のベクトルが関わっており、これらを用いて文脈を考慮した単語の表現が実現されています。その過程はやや複雑なので、ここではなるべく簡単かつ具体的にそれを解説することを目指します。
LLMや生成AIが浴びる注目もあり、Query・Key・ValueはG検定や専門書で出現する頻度は低くないと思うので、この機会にぜひ理解を深めてください。
Query・Key・Valueとは
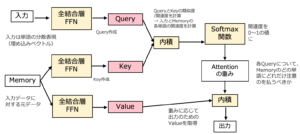
TransformerにおけるAttentionでは、文章中の単語同士の関係(重み)を計算するために、各々の入力単語を Query(クエリ)・Key(キー)・Value(バリュー) という3つのベクトルに変換して処理を行っています。
直感的には、以下のように解釈することができます。
- Query:入力データの中で検索したいもの
- Key:どのような情報をもっているのか
- Value: 実際に抽出された情報
Attentionでは、まず特定の単語のQueryと、文章中の各単語のKeyとのベクトル類似度を計算します。この類似度がAttentionの重みとして採用されます。つまり、単語Aを理解するために、ほかの単語B、単語C、単語D、…にどれだけ注目すべきかを表しています。QueryとKeyのベクトルが似ているほど、Attentionの重みが大きい
次に、上記で得られた重みを各単語のValueに掛け合わせ、加重平均を計算します。その結果は、周囲の単語の情報を取り込んだ「文脈」を反映した新しい単語の情報となります。
KeyとValueは各単語に関する1つセットの辞書型データです。
文脈を考慮した単語表現の計算
AttentionではQuery・Key・Valueを用いることで、文章中の単語同士の関係を柔軟に捉え、文脈を考慮した単語表現を生成することができます。
具体的に、ある単語の文脈表現を作るために他の単語のValueベクトルを重み付きで足し合わせています。つまり、各単語に対応する埋め込みベクトルの加重平均をとります。
ここで例として、「洋菓子」という単語の概念を表現したいケースを考えます。簡単のために「ケーキ」、「を」「食べる」の3つの単語との関係性のみ考慮するとします。
文脈ベクトルは以下のように、Valueと重みを掛けたものを全て足し合わせることで計算されます。
0.60 × Value(ケーキ)+ 0.05 × Value(を)+ 0.35 × Value(食べる)
各々のValueに対応する重み(0.60、0,05、0.35)はQuery と Key の内積で得られています。ちなみに、重みはsoftmax関数 によって確率分布として正規化されるため、すべての重みの合計 = 1となります。
上記の加重平均によって周囲の単語の情報を取り込んだ単語表現(文脈表現)が得られます。