
緊急事態宣言が続いて最近外食してないなぁと思うことが多い。
外食したいと思うけど、特筆して店に詳しいわけでもない。
今回は美味しいお店を自動抽出する方法を検討した。
1. 抽出対象のお店
今回は「食べログ」に登録された店舗から選定することにした。
日本全国にすると範囲が広すぎるため、東京都の店舗に絞った。
店舗情報はスクレイピングにより抽出した。とりあえず抽出項目は以下の5種とした。
・店舗名
・評価スコアの平均値
・所在地
・レビュー文
・カテゴリー
実際に抽出した結果がこちら。レビュー文は各店舗最大で20件を抽出することにした。
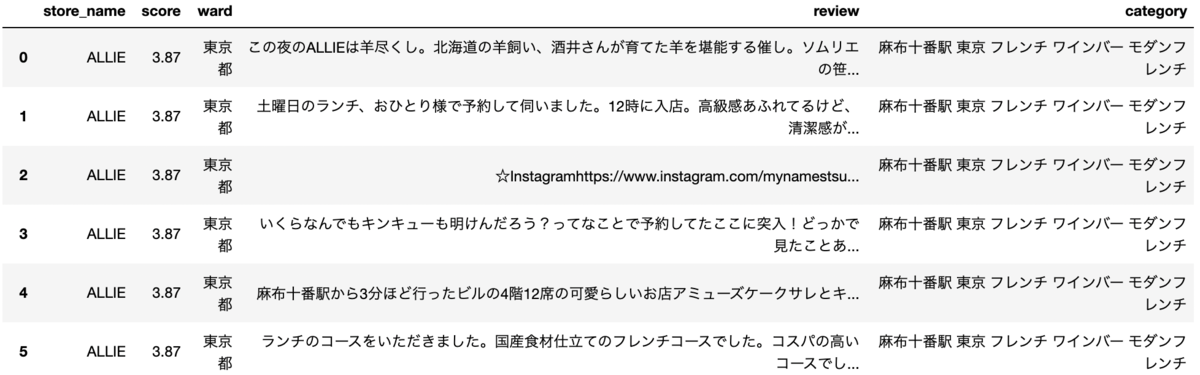
今回はスクレイピングした項目のうち、レビュー文に対して自然言語処理により潜在的に評価の高いお店のランキング付けをしようと思う。
ランキング付けの対象店舗は、スクレイピングを行った396件とした。
2. 分類モデル
レビュー文の評価はネガポジ判定の結果を採用する。
各店舗最大で20件のレビュー文をスクレイピングしているため、レビュー文ごとにネガポジ判定を行い、判定スコアの平均値をその店舗の最終スコアとして扱う。
ネガポジ判定には辞書として東工大が公開する単語感情極性対応表を用いた。
「美味しいお店」抽出のため、食べ物に対する評価として使用されやすい形容詞のみに絞ったネガポジ判定を行う。
この単語感情極性対応表は、各極性単語ごとにスコア値が付与されており、正の極性は「+」、負の極性は「-」となっている。
形態素解析にはMeCabを使用した。
① Bag-of-Words
まずはBag-of-Wordsによるネガポジ判定を試す。
各店舗、各レビュー文ごとに、形容詞を抽出し、辞書内の正負別の極性単語とパターンマッチし、マッチした場合に辞書内の単語に付与されたスコアを加算し、その平均値でスコアリングする。
ランキング付けした結果の内、上位5件、下位5件は以下となった。
一応、下位5件の店名は伏せておく。
最高値で0.81ポイント、最低値で0.12ポイントとそれなりに差異のある結果が得られた。

② Word2Vec
2つ目の手法として、Word2Vecによる分散表現モデルを用いてネガポジ判定を試す。
分散表現モデルは一般公開されたものを使う。(学習済みモデル)
このモデルはFacebookが公開するfastTextモデルであり、日本語Wikipediaを学習コーパスとして利用している。
各店舗ごと、各レビュー内に出現する形容詞の単語と、辞書内の正負別極性単語とのコサイン類似度を算出し、その平均値でスコアリングする。
スコアリングした結果を、以下に示す。
最高値で0.56ポイント、最低値で0.09ポイントとなかなか良い結果が得られた感じ。

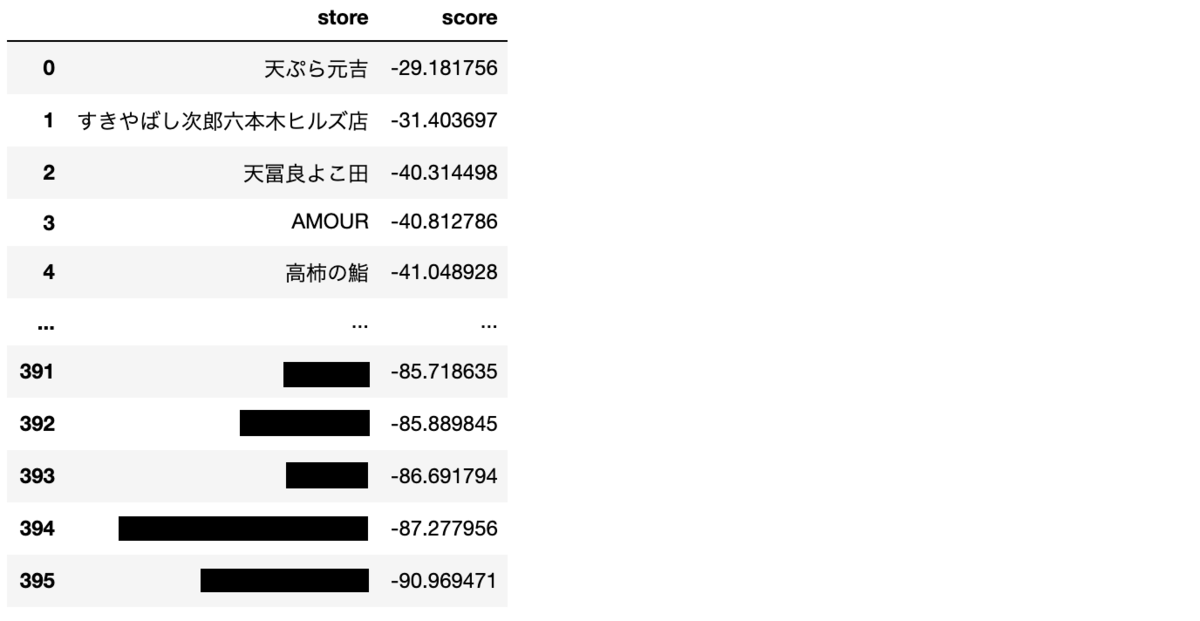
③ Doc2Vec
3つ目のモデルとして、一般公開されたDoc2Vecによる分散表現モデルを用いて実験した。
モデルは、日本語Wikipediaで学習させたものである。(学習済みモデル)
各店舗、各レビュー文内に出現する形容詞の単語集合に対して、辞書内の形容詞とのコサイン類似度を算出し、その平均値でスコアリングした。
ランキング付けした結果を以下に示す。
最もスコアの高い場合でも-29.1ポイントと軒並み低い値となった。
形容詞の単語集合で比較したことが良くなかったのだろうと思う。
3. 最後に
今回は、「食べログ」に登録された店舗のレビュー文に対して、自然言語処理を用いた手法でネガポジ判定を行い、スコアリングにより店舗評価のランキング付けを行った。
Bag-of-Wordsでは、パターンマッチによりマッチした単語の辞書内のスコアを用いてランキング付けした。
対して、Word2VecやDoc2Vecでは、単語のコサイン類似度で算出されたスコアの平均値でスコアリングした。
今回は、レビュー文のみでランキング付けしたが、レビュー文の文字数や各店舗の5段階評価値の平均スコアなども評価指標として取り入れると、もっとおもしろい結果が得られそうだ。
安藤 翼















