
エリアごとの特徴を把握したいとき、データそのものよりマップ上に可視化されたモノを眺めた方が、頭の中にある事前知識も相まって格段に頭が働きやすくなり、議論が活発になります。
日々、企業のデータ利活用をサポートさせていただいている弊社では高速・安価・簡易的に
ロケーションインテリジェンスを促進するツールとしてLLocoという地理空間データセットを開発・販売しております。

本記事ではLLocoとBIツールのTableauの組み合わせで、「こんな感じで郵便番号粒度のエリア特性がチャチャっと掴める」といった一例をご紹介します!
LLocoの特徴
都道府県レベルだと荒く、町丁目レベルだと細かすぎる……
そんな悩みを解決するにはLLocoがうってつけです!
LLocoは郵便番号レベルのポリゴンデータを中心に、各種地域統計データを提供しております。”荒すぎず、細かすぎず”といった点で郵便番号はちょうど良い粒度(汎用的な粒度)になっています。
※1 詳しい提供データ情報はこちら
※2 市区町村レベルのポリゴンデータも提供可
特に商圏分析をする際には郵便番号レベルで分析することをおすすめしております!
※その理由はこちら↓

チャチャっと作ったダッシュボード
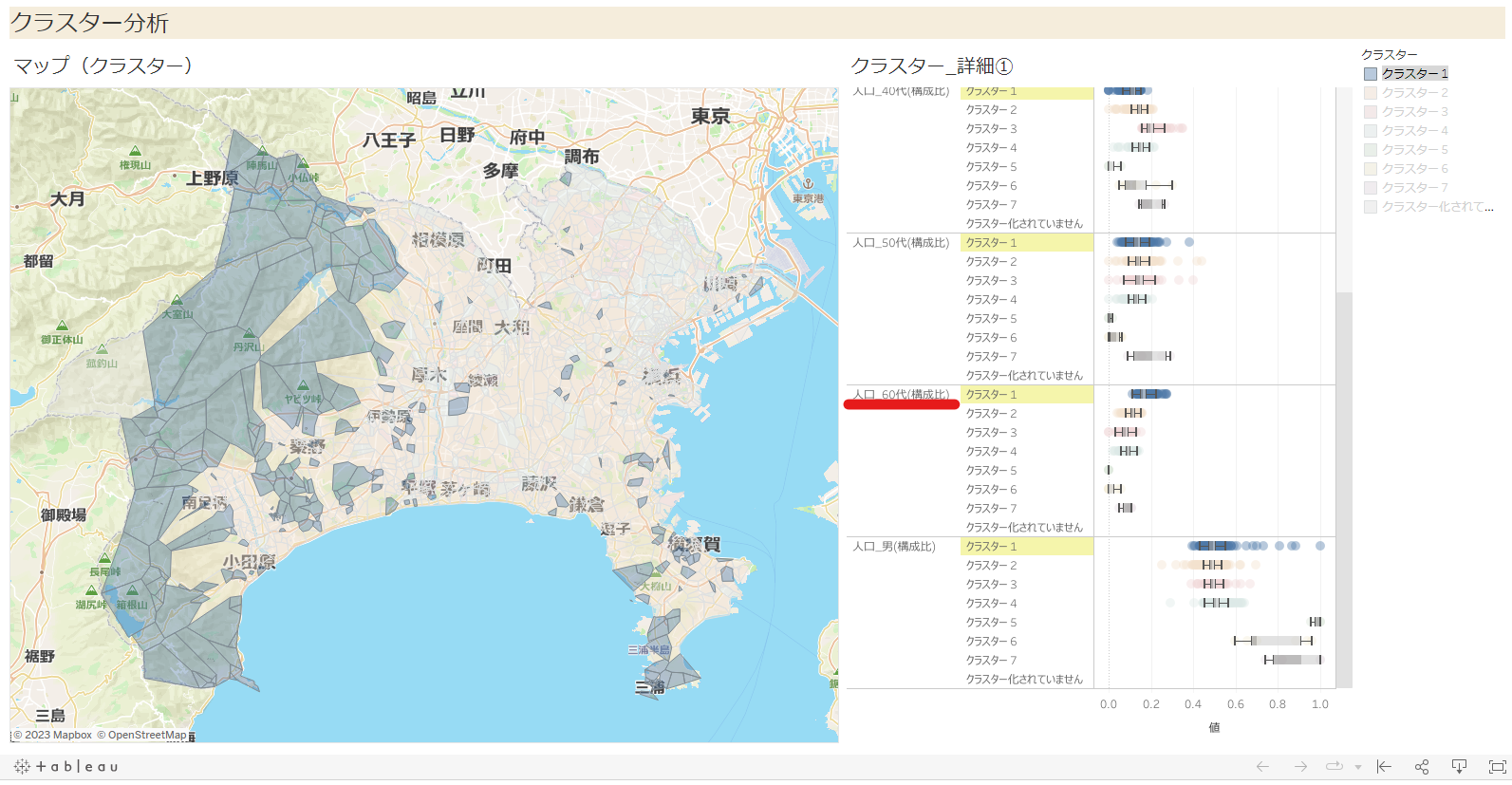
各郵便番号における居住者の性年代の構成比情報(男性比&20,30,40,50,60代比)をもとにクラスター分析を実施し、郵便番号を7つのグループに分けて、その結果をマップ上に可視化することで各郵便番号エリアの大まかな特徴を把握しやすくするダッシュボードを作成しました。左図はクラスタリング結果をマッピングしており、右図では各変数のクラスター別分布を箱ひげ図を用いて表示しています。
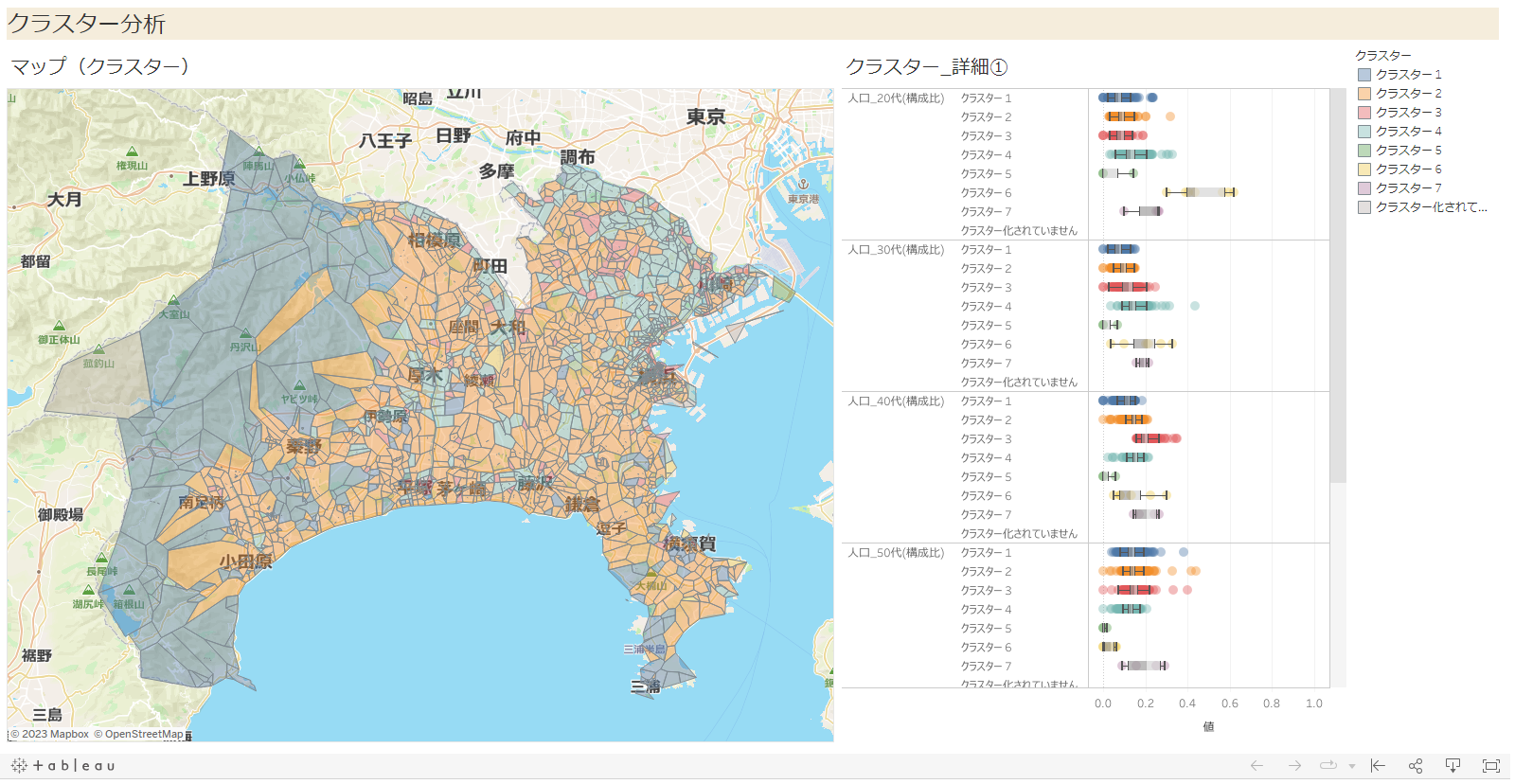
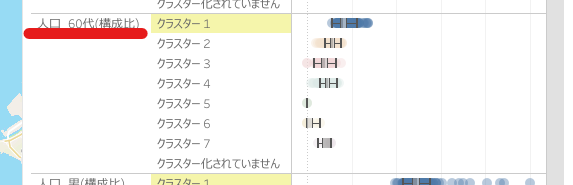
例えばクラスター1の場合、右図から60代の構成比(=60代人口/人口)の箱ひげ図が他のクラスターの箱ひげ図と比べて右側によっていることから、クラスター1はシニア層が比較的多い地域という意味付けができます。
さらに、そのクラスターに属する郵便番号がどのあたりにあるかをマップで確認できるようになっています。
※ダッシュボードはこちら

ちなみに、筆者は今回がLLocoのデータを使うのが初めてで、このダッシュボードを日本シリーズを観ながらダラダラチャチャっと3時間ほどで作成しました。集中度合いで言うと日本シリーズ観戦が7、ダッシュボード作成が3ぐらいだったので、Tableauの利用にある程度慣れている人であれば、集中するとおおよそ3×3/10 = 0.9時間ほどで作成できちゃうと思います!
3回裏終了までには作成できちゃいます!
利用したデータ
- LLocoで提供しているデータ
- simplified_postcode_14_kanagawa.geojson:神奈川県の郵便番号レベルのポリゴンデータ(高速表示用)
- estat_age_population.csv:郵便番号レベルの性別×年齢別人口データ
はい。LLocoで提供しているデータで完結しています。他からデータを引っ張ってくる必要はございません。しかも神奈川県だけだったら無料で使えちゃいます!
作成手順
1. データの接続
Tableau Desktopから先述した2つのデータに接続します。2つのデータは”Postcode Representative”カラムをキーにしてリレーションシップでくっつけておきます。

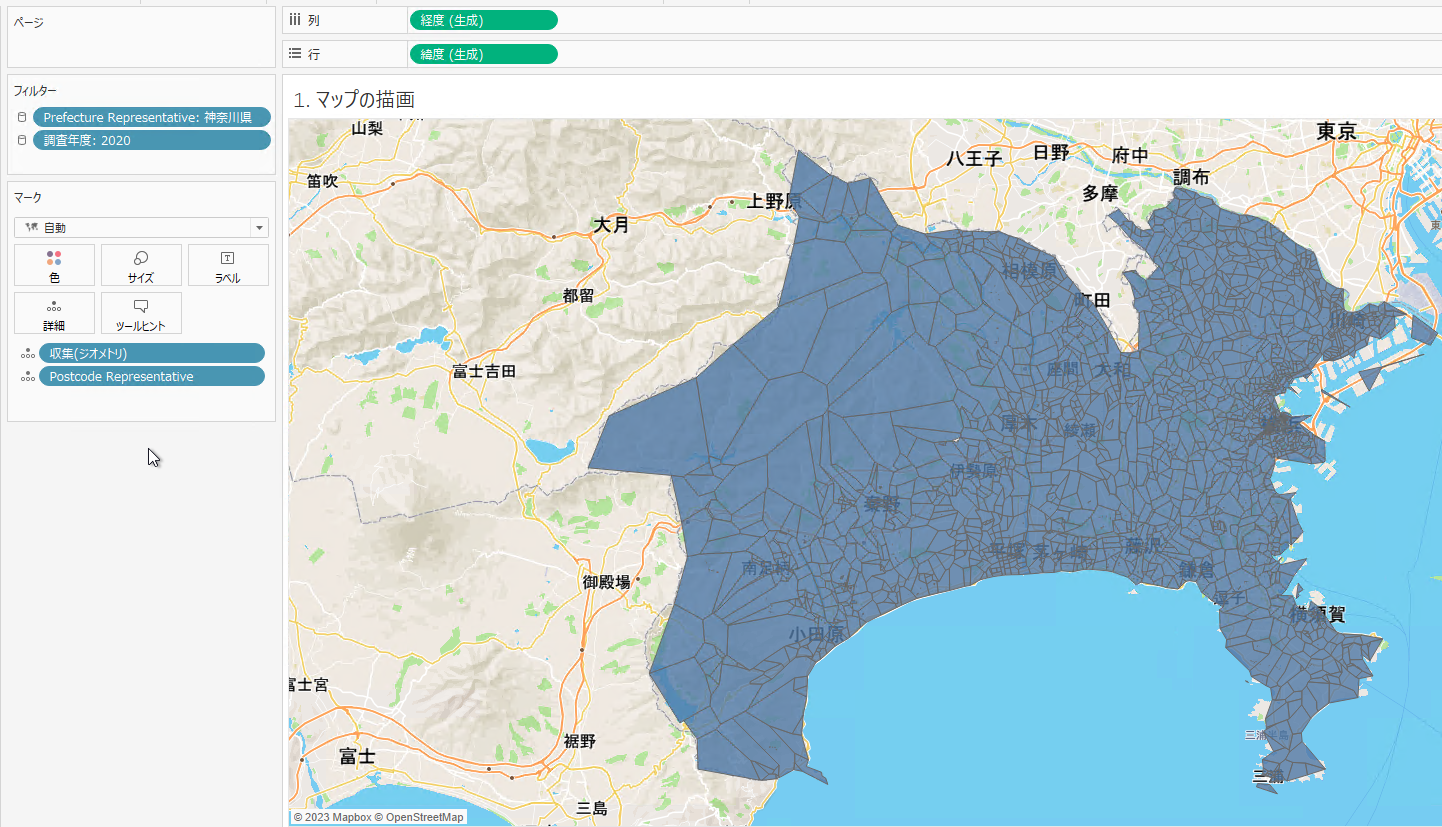
2. マップの描画
まずは下記2つのディメンションをフィルターに追加します。
- Prefecture Representative==”神奈川県”
- 調査年度==2020
次に下記2つのディメンションをマーク>詳細に追加します。
- ジオメトリ
- Postcode Representative
ここまでで郵便番号レベルで区切られたマップが生成されます。
3. 計算フィールドの作成
クラスター分析に用いる変数を計算フィールドで作成します。先述の通り、今回は郵便番号ごとの男性比と20,30,40,50,60代比をもとにクラスターを構成することを目的として、下記計算フィールドを事前に作成しておきます。
- 人口_20代
- 人口_30代
- 人口_40代
- 人口_50代
- 人口_60代
- 人口_男
- 人口_20代(構成比)
- 人口_30代(構成比)
- 人口_40代(構成比)
- 人口_50代(構成比)
- 人口_60代(構成比)
- 人口_男(構成比)
例えば”人口_20代”および”人口_20代(構成比)”の計算フィールドの中身は下記のようになっています。
// 人口_20代
IIF(
[年齢] IN ('20~24歳','25~29歳'),
[人口],
NULL
)
// 人口_20代(構成比)
SUM([人口_20代]) / SUM([人口])他の計算フィールドに関してもIIF文の条件式をよしなに変更して作成していきます。
4. クラスター分析→結果をマップに反映
任意のメジャーをマーク>詳細に追加します。すると、画面左上部にあるアナリティクスからクラスターを選択できるようになりますので、これをシート上にドロップします。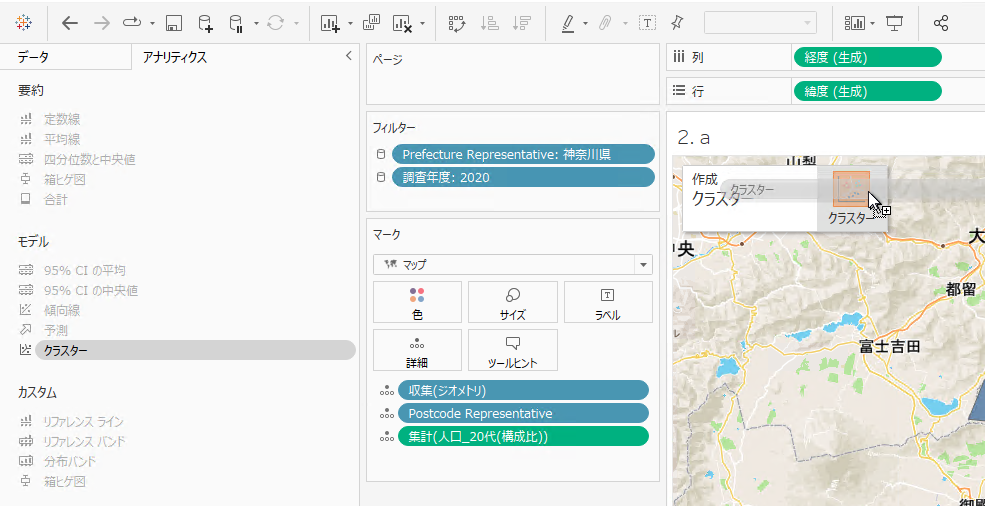
クラスター分析の設定画面が表示されるので、”変数”欄に使用するメジャー、”クラスターの数”欄にクラスター数を設定します。
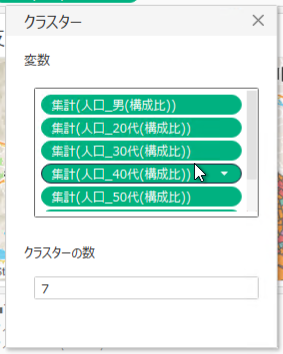
以上でマップは完成です!
さいごに
今回はLLocoで提供しているデータだけでダッシュボードを作成しましたが、ここに自社で保有している店舗への来場者データやサービス契約情報データなどをチャチャっとくっつけて可視化することで、ロケーションインテリジェンスをもとに自社ならではのマーケティング活動に活かすことが可能になります。
ご興味をもっていただいた方は下記ページからお問い合わせください!!












